Figure 1 - program code as a wrapper to a Library function
In order to do something useful with a programming language it is necessary to write code which calls upon the features available in that language. These features may either be provided in the core language itself or by add-on/plug-in libraries. When writing applications which contain large numbers of components, where each component handles a different unit of work from the end user's perspective, the code which is written may be classed as either:
Other words I have seen to classify code in this way are:
The ratio between payload/plumbing or worker/navigation code can also be referred to as the signal-to-noise ratio (SNR).
A programmer will be perceived to be more productive if he can spend more time on the payload and less time on the plumbing. This will require access to additional functions, procedures or components which may be provided by either a library or a framework. These functions are in addition to the core language and provide code which has been written by someone else so that the programmer need not spend time writing his own version. It also saves time in that this pre-written code will (or should) have already been tested and debugged, which is another task that the programmer can cross off his list.
I have used the words "library" and "framework", but what is the difference between the two?
In the world outside of software development a framework is some sort of support structure (e.g. exterior scaffolding or interior frame or chassis) which is used to help build other structures. The framework may be removed after construction, or it may become an integral part of the new structure. When building a software application it is also possible to use a software framework, but most of the "software frameworks" available today do not qualify to use the word "framework" in their names. This is because they do not actually offer any sort of support structure, instead all they are is a collection of loose parts which you have to assemble yourself. In my humble opinion they are libraries, not frameworks. The difference can be summarised as:
The general description of a framework goes as follows:
In general, a framework is a real or conceptual structure intended to serve as a support or guide for the building of something that expands the structure into something useful.
a supporting structure around which something can be built
So if a thing does not have a recognisable structure then it cannot be called a framework. Note also that in the physical world a framework may be absorbed into or integrated with whatever it is used to build, or it may be disassembled and taken away so that it can be used to construct something else. It the software world it would be unusual to use a framework to generate an application then not use that framework to also run the application.
A definition of a software framework is slightly different:
The following definition is from WikiPedia:
In computer programming, a software framework is an abstraction in which software providing generic functionality can be selectively changed by user code, thus providing application specific software. A software framework is a universal, reusable software platform used to develop applications, products and solutions. Software frameworks include support programs, compilers, code libraries, an application programming interface (API) and tool sets that bring together all the different components to enable development of a project or solution.
It also identifies the following key distinguishing features that separate frameworks from normal libraries:
- Inversion of control: In a framework, unlike in libraries or normal user applications, the overall program's flow of control is not dictated by the caller, but by the framework.
- Default behavior: A framework provides basic default behavior from working templates.
- Extensibility: A framework can be extended by the user usually by selective overriding of a template or specialized by user code to provide specific functionality.
- Non-modifiable framework code: The framework code, in general, is not supposed to be modified, while accepting user-implemented extensions. In other words, users can extend the framework, but should not modify its code.
It goes on to say the following:
The designers of software frameworks aim to facilitate software developments by allowing designers and programmers to devote their time to meeting software requirements rather than dealing with the more standard low-level details of providing a working system, thereby reducing overall development time.
To put it another way, the framework provides as much plumbing as possible so that the developers can devote their time to the payload.
In the book Design Patterns: Elements of Reusable Object-Oriented Software which was first published in 1994 the authors wrote the following:
A framework is a set of cooperating classes that make up a reusable design for a specific class of software. The framework dictates the architecture of your application. It will define the overall structure, its partitioning into classes and objects, the key responsibilities thereof, how the classes and objects collaborate, and the thread of control. A framework predefines these design parameters so that you, the application designer/implementer, can concentrate on the specifics of your application. The framework captures the design decisions that are common to its application domain. Frameworks thus emphasized design reuse over code reuse, though a framework will usually include concrete subclasses you can put to work immediately.
In my case my area of expertise is in the building of enterprise applications which are characterised by having web pages at the front-end, a relational database at the back-end, and software in the middle to handle the business rules. This allows the user to put data into and get data out of the relational database while executing sets of different business rules. There may be several different business areas (domains) which are covered by the application, such as product data, order processing, invoicing, inventory, shipments, et cetera. Each of these is developed as a separate subsystem with its own database and its own set of tasks, but these subsystems are run from within the framework and are allowed to communicate with one another in order to share both processing and data.
It goes on to say the following:
Reuse on this level leads to an inversion of control between the application and the software on which it is based. When you use a toolkit (or a conventional subroutine for that matter), you write the main body of the application and call the code you want to reuse. When you use a framework, you reuse the main body and write the code it calls. You'll have to write operations with particular names and calling conventions, but that reduces the design decisions you have to make.
Not only can you build applications faster as a result, but the applications have similar structures. They are easier to maintain, and they seem more consistent to their users. On the other hand, you lose some creative freedom, since many design decisions have been made for you.
When it says you reuse the main body and write the code it calls
it means that you run a framework component in order to call the code that you write. If your framework does not have a runnable component then how can it be called a framework?
Later on it says:
Frameworks are becoming increasingly common and important. They are the way that object-oriented systems achieve the most reuse.
In a later section it describes the Template Method Pattern using these words:
Template methods are a fundamental technique for code reuse. They are particularly important in class libraries because they are the means for factoring out common behaviour in library classes.
Template methods lead to an inverted control structure that's sometimes referred to as the Hollywood Principle that is, "Don't call us, we'll call you". This refers to how a parent class calls the operations of a subclass and not the other way around.
In the book Applying UML and Patterns, which was first published in 1997, the author Craig Larman writes the following:
38.4 What is a Framework?At the risk of oversimplification, a framework is an extendable subsystem for a set of related services, such as:
- Graphical user interface frameworks (for example, Microsoft Foundation Classes, Smalltalk-80 Model-View-Controller).
- Persistence frameworks (that is, services to make persistent objects).
In general a framework:
- Is a cohesive set of classes that collaborate to provide services for the core, unvarying part of a logical subsystem.
- Contains concrete (and especially) abstract classes that define interfaces to conform to, object interactions to participate in, and other invariants.
- Usually (but not necessarily) requires the framework user to define subclasses of existing framework classes in order to make use of, customise, and extend the framework services.
- Has abstract classes that may contain both abstract and concrete methods.
- Relies on the Hollywood Principle -
Don't call us, we'll call you.This means that the user-defined classes (for example, new subclasses) will receive messages from the predefined framework classes. These are usually handled by implementing superclass abstract methods.
Notice here that he specifically mentions the use of abstract classes, which are part of the framework, to provide invariant or unvarying parts of a logical subsystem. He then says that the framework user (that is, the developer) can extend the framework classes to use, customise and extend the framework services by defining subclasses. The use of abstract classes for invariant behaviour, subclasses for customisable behaviour, and the Hollywood Principle whereby the subclasses receive messages from the predefined framework classes come together and are expanded upon in the section on the Template Method Pattern which says:
38.11 Framework Design - Template Method PatternThe next section describes some of the essential design features of the Database Brokers, which are a central part of the persistence framework. These design features are based on the Template Method GoF pattern [GHJV95].
This pattern is at the heart of framework design. The idea is to define a method (the Template Method) in a superclass that defines the skeleton of an algorithm, with its varying and unvarying parts. The Template Method invokes other methods, some of which are operations which may be overridden in a subclass.
Thus, subclasses can override the varying methods in order to add their own unique behaviour at points of variability.
The Template Method pattern illustrates the Hollywood Principle -
Don't call us, we'll call you.
The Hollywood Principle is now formally referred to as Inversion of Control.
In the article Applying Patterns and Frameworks to Develop Object-Oriented Communication Software (PDF), which was first published in 1997, the author Douglas C. Schmidt writes the following:
2.2.2 The Benefits of Frameworks
Although knowledge of patterns helps to reduce development effort and maintenance costs, reuse of patterns alone is not sufficient to create flexible and efficient communication software. While patterns enable reuse of abstract design and architecture knowledge, abstractions documented as patterns do not directly yield reusable code. Therefore, it is essential to augment the study of patterns with the creation and use of application frameworks. Frameworks help developers avoid costly re-invention of standard communication software components by implementing common design patterns and factoring out common implementation roles.
If you look at the structure diagram in Figure 3 you will see that each user transaction (task) is implemented as a group of components which each have a particular responsibility. These are not components that have to be built by the developer, they are working implementations of those design patterns. The Controllers, Views and DAOs have been pre-built and are supplied in the framework as they do not contain any application logic. This is the sole responsibility of the Model components which exist in the Business layer, and these are generated by the framework to conform to a standard pattern. They initially do not contain any code apart from a constructor as all the standard behaviour is supplied using Template Methods which are inherited from an abstract table class. Unique behaviour can be added in later by inserting code in any of the pre-defined "hook" methods.
He also wrote:
2.2.3 Relationship Between Frameworks and Other Reuse Techniques
Frameworks provide reusable software components for applications by integrating sets of abstract classes and defining standard ways that instances of these classes collaborate [Components, Frameworks, Patterns by Ralph E. Johnson]. The resulting application skeletons can be customized by inheriting and instantiating from reusable components in the frameworks.
The scope of reuse in a framework can be significantly larger than using traditional function libraries or conventional OO class libraries. The increased level of reuse stem from the fact that frameworks are tightly integrated with key communication software tasks such as service initialization, error handling, flow control, event processing, and concurrency control. In general, frameworks enhance class libraries in the following ways:
- Frameworks define "semi-complete" applications that embody domain-specific object structures and functionality:
Class libraries provide a relatively small granularity of reuse. In contrast, components in a framework collaborate to provide a customizable architectural skeleton for a family of related applications. Complete applications can be composed by inheriting from and/or instantiating framework components. This reduces the amount of application-specific code since much of the domain-specific processing is factored into the generic components in the framework.- Frameworks are active and exhibit "inversion of control" at run-time:
Class libraries are typically passive i.e., they perform their processing by borrowing threads of control from self-directed application objects. In contrast, frameworks are active, i.e., they manage the flow of control within an application. This "inversion of control" is referred to as the Hollywood Principle, i.e., "don't call us, we'll call you."
Where he mentions application-specific code
you could use payload, and where he mentions domain-specific processing
you could use plumbing.
The idea that frameworks define "semi-complete" applications means to me that a framework is a runnable application with its own GUI and database (which identifies the application components) but which does not do anything which is actually useful to the end user. A developer uses the facilities provided within the framework to generate the various components for an application, and this allows the end user to run that application by going through the framework in order to choose which component to run.
In the article Designing Reusable Classes which was published in 1988 the authors Ralph E. Johnson & Brian Foote wrote the following:
Introduction
A framework is a set of classes that embodies an abstract design for solutions to a family of related problems, and supports reuses at a larger granularity than classes. During the early phases of a system's history, a framework makes heavier use of inheritance and the software engineer must know how a component is implemented in order to reuse it. As a framework becomes more refined, it leads to "black box" components that can be reused without knowing their implementations.
Toolkits and Frameworks
One of the most important kinds of reuse is reuse of designs. A collection of abstract classes can be used to express an abstract design. The design of a program is usually described in terms of the program's components and the way they interact.
An object-oriented abstract design, also called a framework, consists of an abstract class for each major component. The interfaces between the components of the design are defined in terms of sets of messages. There will usually be a library of subclasses that can be used as components in the design.
...
Frameworks are useful for reusing more than just mainline application code. They can also describe the abstract designs of library components. The ability of frameworks to allow the extension of existing library components is one of their principal strengths.
...
Each component in such a library can serve as a discrete, stand-alone, context independent part of a solution to a large range of different problems. Such components are largely application independent.
A framework, on the other hand, is an abstract design for a particular kind of application, and usually consists of a number of classes. These classes can be taken from a class library, or can be application-specific.
Frameworks provide a way of reusing code that is resistant to more conventional reuse attempts. Application independent components can be reused rather easily, but reusing the edifice that ties the components together is usually possible only by copying and editing it. Unlike skeleton programs, which is the conventional approach to reusing this kind of code, frameworks make it easy to ensure the consistency of all components under changing requirements.
Since frameworks provide for reuse at the largest granularity, it is no surprise that a good framework is more difficult to design than a good abstract class. Frameworks tend to be application specific, to interlock with other frameworks by sharing abstract classes, and to contain some abstract classes that are specialized for the framework. Designing a framework requires a great deal of experience and experimentation, just like designing its component abstract classes.
Note here that the type of application which is specifically addressed by the RADICORE framework is that of a database application with an HTML front end.
White-box vs. Black-box Frameworks
One important characteristic of a framework is that the methods defined by the user to tailor the framework will often be called from within the framework itself, rather than from the user's application code. The framework often plays the role of the main program in coordinating and sequencing application activity. This inversion of control gives frameworks the power to serve as extensible skeletons. The methods supplied by the user tailor the generic algorithms defined in the framework for a particular application.
A framework's application specific behavior is usually defined by adding methods to subclasses of one or more of its classes. Each method added to a subclass must abide by the internal conventions of its superclasses. We call these white-box frameworks because their implementation must be understood to use them.
Here they are referring to the Template Method Pattern and the use of "hook" methods.
The major problem with such a framework is that every application requires the creation of many new subclasses. While most of these new subclasses are simple, their number can make it difficult for a new programmer to learn the design of an application well enough to change it.
This does not apply to the RADICORE framework as a new subclass need only be created for each new database table, but these are generated by the framework so do not require much effort.
A second problem is that a white-box framework can be difficult to learn to use, since learning to use it is the same as learning how it is constructed.
Anybody who has already written a program which uses HTML forms to maintain the contents of a database table should already know the various steps in its processing flow, so should be able to easily identify that part of the framework where each step is performed. It's not rocket science.
Another way to customize a framework is to supply it with a set of components that provide the application specific behavior. Each of these components will be required to understand a particular protocol. All or most of the components might be provided by a component library. The interface between components can be defined by protocol, so the user needs to understand only the external interface of the components. Thus, this kind of a framework is called a black-box framework.
Simply creating a subclass for each database table is not good enough as all that does is create a object in the Busness/Domain layer where all the standard methods are inherited from the abstract class. It is also necessary to create the components in the Presentation layer which call those methods on a particular subclass in order to perform a task required by the user. Again this is a simple procedure as the Data Dictionary can be used to combine a database table with a Transaction Pattern in order to generate a component script and a screen structure script.
Black-box frameworks like the pluggable views are easier to learn to use than white-box frameworks, but are less flexible. Pluggable views are usually sufficient to describe user interfaces that display only text, but the user who wants a more graphical user interface will have to use the original MVC framework. Fortunately, pluggable views fit into the MVC framework well, so the user only has to create components to handle the graphical aspects of the interface.
Web applications do not use a bit-mapped graphical user interface which responds to mouse clicks, they use an HTML form which responds only to a SUBMIT button. Receiving an HTML request and returning an HTML response is much simpler.
One way of characterizing the difference between white-box and black-box frameworks is to observe that in white-box frameworks, the state of each instance is implicitly available to all the methods in the framework, much as the global variables in a Pascal program are. In a black-box framework, any information passed to constituents of the framework must be passed explicitly. Hence, a white-box framework relies on the intra-object scope rules to allow it to evolve without forcing it to subscribe to an explicit, rigid protocol that might constrain the design process prematurely.
The state of each table object is held in a standard $fieldarray property which holds the data for each column within that database table. While this array is passed from the Controller into the Model in the form of the $_POST array, and then injected into the View using the getFieldArray() method, no framework component (apart from data validation and data formatting) contains any references to the state of any object. The standard protocols which are available in the abstract table class have been used to develop at least 20 different subsystems over a period of 20 years, so I think it is fair to say that they do not "constrain the design process prematurely".
A framework becomes more reusable as the relationship between its parts is defined in terms of a protocol, instead of using inheritance. In fact, as the design of a system becomes better understood, black-box relationships should replace white-box ones. Black-box relationships are an ideal towards which a system should evolve.
RADICORE is a white-box framework in that it uses inheritance from an abstract table class coupled with the Template Method Pattern so that predefined "hook" methods can be overridden in concrete subclasses.
Toolkits
An object-oriented application construction environment, or toolkit, is a collection of high level tools that allow a user to interact with an application framework to configure and construct new applications.
Components in an application subsystem are constructed using the Data Dictionary into which the structures of all the tables in the application database have been imported. Once constructed each component can be run from with the Role-Based Access Control (RBAC) part of the framework. The standard framework components provide all the standard boilerplate code while any domain specfic code can be subsequently inserted into any domain object. In this way the framework components are domain-agnostic as all domian knowledge is held with the domain objects which are created by the developer.
I came across this reason in What is a Framework in Programming & Why You Should Use One from netsolutions.com:
The purpose of a framework is to assist in development, providing standard, low-level functionality so that developers can focus efforts on the elements that make the project unique. The use of high-quality, pre-vetted functionality increases software reliability, speeds up programming time, and simplifies testing.
Ultimately, frameworks are used to save time and money.
You should also bear in mind that there may be a large number of frameworks out there which you could use, but do not think that they are all the same. Most are general purpose frameworks which could be used in a wide variety of applications, but to help you achieve the best results you should try to find a framework that specialises in your particular problem domain. In 2004 I came across the following post in a forum on www.sitepoint.com written by someone with the moniker of selkirk:
Circa 1996, I was asked to analyze the development processes of two different development teams.Team A's project had a half a million lines of code, 500 tables, and over a dozen programmers. Team B's project was roughly 1/6 the size.
Over the course of several months, management noticed that team A was roughly twice as productive as team B. One would think that the smaller team would be more productive.
I spent several months analyzing the code from both projects, working on both projects and interviewing programmers. Finally I did an exercise which lead to an epiphany. I counted each line of code in both applications and assigned them to one of a half a dozen categories: Business logic, glue code, user interface code, database code, etc.
If one considers that in these categories, only the business logic code had any real value to the company. It turned out that Team A was spending more time writing the code that added value, while team B was spending more time gluing things together.
In the 70s an AI researcher named Doug Lenat wrote a program called AM that could discover mathematical proofs. One of the arguments against this actually being an example of computer creativity is that AM used a very rich notational language in his problem domain (mathematics). Even generating random symbols in this notation made it hard not to come up with a proof of some kind.
Team A had a set of libraries which was suited to the task which they were performing. Team B had a set of much more powerful and much more general purpose libraries.
So, Team A was more productive because the vocabulary that their tools provided spoke "Their problem domain," while team B was always translating. In addition, team A had several patterns and conventions for doing common tasks, while Team B left things up to the individual programmers, so there was much more variation. (especially because their powerful library had so many different ways to do everything.)
The conclusion I drew from this is that you can be more productive if the toolset that you use is tuned to your particular problem domain rather than being a general purpose jack of all trades, master of none toolset which offers lots of low level options which you have to stitch together. That is why I say that if you are writing an enterprise application then you would be better off using a framework that was designed specifically for enterprise applications. If your application is starting small but growing over time with the addition of more database tables and more business logic, then you would be better off using a framework that was designed to build working code from database structures into which business logic could then be added.
It was also obvious to me that regardless of the number of database tables and the different data that they stored the protocols for accessing that data - through the standard CRUD operations - were always the same and therefore could easily be built into a reusable component. Virtually every task (user transaction) follows the same pattern:
Similary the rules for building HTML web pages are not concerned with the type of data which is being handled. In an enterprise application which has thousands of web pages an experienced programmer should be able to recognise repeating structures in those web pages, should be able to define these structures in tremplates, and then be able to build a process which merges any set of application data with a template in order to produce a complete HTML web page. In the RADICORE framework the templating engine is XSL - the standard View component extracts the data from the Model, converts it into XML, then transforms it into HTML using an XSL stylesheet.
Be aware that the world is awash with offerings which label themselves as "frameworks" but which are actually nothing but libraries.
The shortest definition I have seen can be expressed thus:
This is now formally referred to as Inversion of Control or the Hollywood Principle.
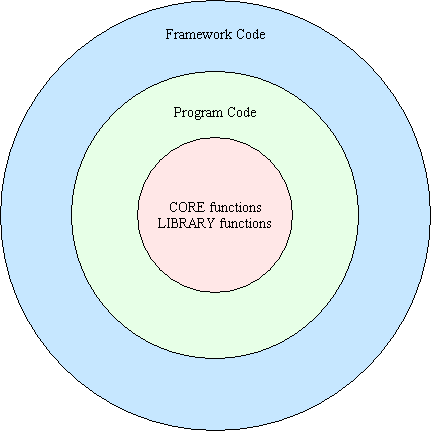
Libraries provide functions or APIs which are in addition to those provided by the core language. To make use of one of these functions the programmer must write his own code, or wrapper, to call the function, as shown in Figure 1:
Although this does help reduce the amount of code that a programmer has to write in order to perform a specific task in a single component, it does not help reduce by a significant amount the volume of plumbing code in an entire application which is comprised of many components.
A true framework is therefore a structure that provides wrappers for the program code, as shown in Figure 2:
How can such wrappers be provided? Each task in a database application follows a similar pattern - it has an HTML screen at the front end, an SQL database at the back end, and software in the middle to handle the business rules. Data is inserted at the front end, processed in the middle, then stored in the back end. Later on it can be retrieved from the back end, processed in the middle, then displayed on the front end. Although the data may be different and the business rules may be different, the basic processing of each task is the same - it performs one or more CRUD operations on one or more database tables.
The movement of data back and forth involves several steps. It does not matter what the data is, the steps are always the same. The steps for dealing with HTML requests and responses are always the same, the steps for dealing with SQL queries are always the same, the steps in the business layer are basically the same, but they have to deal with business rules which are unique for each database table.
In a paper called Designing Reusable Classes which was published in 1988 by Ralph Johnson and Brian Foote it describes a technique for software reuse called programming-by-difference. This is where you isolate the similarities from the differences so that the similarities can be handled in standard code and the differences can be handled in custom code. This "standard code" (the plumbing) could either be provided in pre-compiled service components which can be built into the framework and used "out of the box", or it could be provided in an abstract class which could be extended by a developer into a subclass so that custom implementations (the payload) can be inserted into "hook" methods. The difference is that in a framework it is the standard framework code which calls the developer's code whereas in a library it is the other way around.
This is not to be confused with the Dependency Inversion Principle (DIP) which switches between different objects instead of different method implementations in subclasses. It is also known as the Hollywood Principle.
The following definition can be found in wikipedia:
In software engineering, inversion of control (IoC) is a programming principle. IoC inverts the flow of control as compared to traditional control flow. In IoC, custom-written portions of a computer program receive the flow of control from a generic framework. A software architecture with this design inverts control as compared to traditional procedural programming: in traditional programming, the custom code that expresses the purpose of the program calls into reusable libraries to take care of generic tasks, but with inversion of control, it is the framework that calls into the custom, or task-specific, code.
The earliest definition I found was in Components, Frameworks, Patterns which was published in 1997:
One of the characteristics of frameworks is inversion of control. Traditionally, a developer reused components from a library by writing a main program that calls the components whenever necessary. The developer decides when to call the components, and is responsible for the overall structure and flow of control of the program. In a framework, the main program is reused, and the developer decides what is plugged into it and might even make some new components that are plugged in. The developers code gets called by the framework code. The framework determines the overall structure and flow of control of the program.
Another definition can be found in Designing Reusable Classes which was published in 1988. It contains the following:
One important characteristic of a framework is that the methods defined by the user to tailor the framework will often be called from within the framework itself, rather than from the user's application code. The framework often plays the role of the main program in coordinating and sequencing application activity. This inversion of control gives frameworks the power to serve as extensible skeletons. The methods supplied by the user tailor the generic algorithms defined in the framework for a particular application.
A framework's application specific behavior is usually defined by adding methods to subclasses of one or more of its classes. Each method added to a subclass must abide by the internal conventions of its superclasses.
This principle has come to be known as the Hollywood Principle (don't call us, we'll call you) which was first used in a paper by Richard E. Sweet which was published in 1985. In the books which I referenced earlier, one by the Gang of Four and the other by Craig Larman, they both mention the Template Method Pattern as being the best design pattern for implementing inversion of control.
The concept of inversion of control, where it is the framework that calls the developer's code instead of the other way around, can be implemented at two separate levels
After individual application tasks have been developed and their identities and runtime characteristics have been fed into the framework's repository, the user should then run the framework GUI in order to choose which application component (task) to run. This is so that the framework can ensure that a particular task can only be run by a user who is authorised to do so, and to ensure that it is supplied with the correct runtime arguments. This processing is facilitated by the following tables in the MENU database:
A user cannot gain access to the system until he/she passes through the LOGON screen. The system will then perform the following steps:
If the user selects an option in the menu bar what happens next depends on that option's task_type:
Every task has an entry on the MNU_TASK table where the script_id points to a component script on the file system within that subsystem's subdirectory. This script identifies three different components:
Note that the the Model class will inherit all its standard behaviour from an abstract table class. Each method called by a Controller on a Model exists in the abstract class as an implementation of the Template Method Pattern which contains a mixture of invariant and variable methods. The invariant methods contain standard behaviour while the variable methods, which are empty "hook" methods, are designed to be overridden in any subclass in order to provide custom behaviour which is specific to that subclass.
RADICORE is not a library of loose components which the developer has to assemble into a working application, it is a fully-fledged framework which satisfies all the conditions identified in What is a framework? as shown in these distinguishing features.
It is not a general-purpose framework which can be used to build any sort of public-facing website, it was designed specifically for web-base enterprise applications which allow an enterprise to record its business activities. These applications are characterised by having HTML forms at the front end, a relational database at the back end, and software in the middle to handle the business rules. The framework provides a skeleton structure for every component within an application subsystem so that the developer can spend his time on the application-specific code (the payload) instead of the boilerplate framework code (the plumbing).
While each subsystem that you may build will have a different database, a different set of tasks and a different set of business rules, all those differences are handled in a similar manner. Every application subsystem requires the creation of the following scripts:
Note that all of the above scripts are generated from the Data Dictionary using the framework's GUI and do not have to created by hand.
The distinguishing features which separate a framework from a library are provided in the RADICORE framework as follows:
In his book Visualising Software Architecture the author Simon Brown makes the following complaint:
Ask somebody in the building industry to visually communicate the architecture of a building and you'll likely be presented with site plans, floor plans, elevation views, cross-section views and detail drawings. In contrast, ask a software developer to communicate the software architecture of a software system using diagrams and you'll likely get a confused mess of boxes and lines.
I've asked thousands of software developers to do just this over the past decade and continue to do so today. The results still surprise me, with the thousands of photos taken during these software architecture sketching workshops suggesting that effective visual communication of software architecture is a skill that's sorely lacking in the software development industry.
The Gang of Four book has the following to say on framework design:
If applications are hard to design, and toolkits are harder, then frameworks are hardest of all. A framework designer gambles that one architecture will work for all applications in the domain. Any substantive changes to the framework's design would reduce its benefits considerably, since the framework's main contribution to an application is the architecture it defines. Therefore it is imperative to design the framework to be as flexible and extensible as possible.
Furthermore, because applications are so dependent on the framework for their design, they are particularly sensitive to changes in framework interfaces. As a framework evolves, applications have to evolve with it. That makes loose coupling all the more important; otherwise even a minor change to the framework would have major repercussions.
The design issues just discussed are most critical to framework design. A framework that addresses them using design patterns is far more likely to achieve high levels of design and code reuse than one that doesn't. Mature frameworks usually incorporate several design patterns. The patterns help make the framework's architecture suitable to many different applications without redesign.
Because it was designed specifically for enterprise applications with HTML forms at the front end, an SQL database at the back end, and business rules in the middle, it has an architecture which should be familiar to anyone who develops such applications. Its structure is a combination of the 3-Tier Architecture with its Presentation, Business and Data Access layers, and the MVC design pattern with its Model, View and Controller components, as shown in Figure 3:
Figure 3 - Model-View-Controller plus 3-Tier Architecture
")
Note that the small boxes in the above diagram do not represent single components but types of component. Each of these components falls into one of two types:
The components in the RADICORE framework fall into the following categories:
It should also be noted that:
This arrangement helps me to provide these levels of reusability which in turn means that the effort required to generate application components is much less than is possible in other frameworks, especially the faux frameworks.
A more detailed structure diagram which identifies every major component within the framework is shown in Figure 4:
Figure 4 - detailed structure diagram
")
Note: each of the boxes in the above diagram is a clickable link.
In any modular system the way that Coupling and Cohesion are dealt with has a direct effect on the maintainability of the system, with high cohesion and loose coupling being the most desirable.
Note that every framework component uses this structure, and every component that you generate for your end-user application uses exactly the same structure.
RADICORE is not a general-purpose framework which can be used to write any type of application, it was designed specifically for one type of application only - an enterprise application. These applications can be characterised by the fact that they follow a similar pattern: they have a Presentation layer or GUI (Graphical User Interface) at the front end, a Data Access layer (database, usually relational) at the back end, and a Business layer (to execute business rules) in the middle. A complete system is usually made up from a number of smaller subsystems, each of which deals with a specific area of the organisation's business. Each subsystem will usually have its own set of database tables and tasks to view and maintain their contents, though it is usual nowadays for subsystems to share common data instead of having to keep duplicate copies.
Business-facing enterprise applications are are particular type of software application and have a particular set of characteristics and requirements:
Here is the definition of an Enterprise Application from wikipedia:
Enterprise software, also known as enterprise application software (EAS), is computer software used to satisfy the needs of an organization rather than individual users. Enterprise software is an integral part of a (computer-based) information system; a collection of such software is called an enterprise system. These systems handle a number of operations in an organization to enhance the business and management reporting tasks.
Services provided by enterprise software are typically business-oriented tools. As enterprises have similar departments and systems in common, enterprise software is often available as a suite of customizable programs. Enterprise computing is the information technology (IT) tool that businesses use for efficient production operations and back-office support. These IT tools cover database management, customer relationship management, supply chain management, business process management and so on.
Here is a definition of a Enterprise Resource Planning (ERP) application, which is a particular type of Enterprise Application, from pcmag.com:
An integrated information system that serves all departments within an enterprise. Evolving out of the manufacturing industry, ERP implies the use of packaged software rather than proprietary software written by or for one customer. ERP modules may be able to interface with an organization's own software with varying degrees of effort, and, depending on the software, ERP modules may be alterable via the vendor's proprietary tools as well as proprietary or standard programming languages.
An ERP system can include software for manufacturing, order entry, accounts receivable and payable, general ledger, purchasing, warehousing, transportation and human resources.
This type of application can therefore benefit from its own type of framework. Here is a definition of an Enterprise Framework from pcmag.com:
A complete environment for developing and implementing a comprehensive information system. Enterprise frameworks provide pre-built applications, development tools for customizing and integrating those applications to existing ones as well as developing new applications. They may also provide a workflow component. Frameworks such as ERP and CRM are available for business functions such as order entry, inventory and payroll, while frameworks exist for specific industries such as health services and insurance.
Comprehensive and Flexible
There are many software packages for particular functions and industries, and "enterprise framework" may be added to a title as a marketing buzzword. However, an enterprise framework implies a comprehensive, soup-to-nuts [from beginning to end] solution. It also implies flexibility rather than relying only on a fixed set of options.
Enterprise applications are usually comprised of a number of separate but integrated subsystems or modules each of which deals with a specific business area, such as Sales Order processing (SOP), Purchase Order Processing (POP), Supply Chain Management (SCM), Invoicing, Inventory, Shipments, Requests, Requirements and Quotations, Accounting (General Ledger, Accounts Receivable, Accounts Payable), Timesheets and Expenses, et cetera. Each subsystem will usually have its own database and its own set of tasks. A large ERP system may have dozens of subsystems and thousands of tasks.
Note that early enterprise applications may have had each module developed as a separate stand-alone application which did not have the ability to communicate with or share data with other modules. Modern versions are much more sophisticated as each module appears to the user as just another subsystem in a single integrated system where data and functions are shared and not duplicated.
Another major difference between business-facing enterprise applications and public-facing websites is their accessibility:
Because access to an enterprise application is restricted this implies the following requirements:
Before I built my first framework in the 1980s all the bespoke applications which I had designed previously shared the same set of library components, but certain runtime components, although similar, were still built by hand. This included a logon screen, a set of static menu screens, and a hard-coded access control list (ACL). This had to change one day when a client insisted on a system with dynamic menus which hid those menu options which the user was not allowed to access. In order to replace hard-coded screens of static options with a screen of dynamic options I had to have an empty screen which could be filled with data from a database table. I spent a couple of hours one Sunday afternoon in designing a database and the supporting software, and on the following Monday I started coding, with the whole thing up and running by the Friday afternoon. Documentation for this can be found on my COBOL page. The database had tables for users, tasks (user transactions), menus and task access, with proper maintenance screens for each of these tables. Not only was this design a success on that project, but it was also adopted by the company as the standard front end for all subsequent projects as it provided essential processing that no longer had to be duplicated. This meant that all the developers had to do was build their application components and plug them into the framework, thus becoming more productive.
RADICORE is the latest version of this original framework, but with an updated database along with updated functionality. It is a system which is comprised of a number of subsystems, each with its own database, its own directory structure in the file system, and its own set of entries in the MENU database. The framework itself is composed of the following core subsystems:
Extra subsystems for end-user applications can be added as and when required. Simply create your database, import the details into the Data Dictionary, then generate your application components. While the database structures and the business rules for each subsystem are different, all these differences are confined to the Business layer. The way that the data is handled within the Presentation and Data Access layers is standard and can be provided by pre-written framework components. After creating your application components they can be accessed through the framework GUI from buttons in either the menu bar or a navigation bar.
The following statements were taken from Object-Oriented Application Frameworks which was published in 1997 by Mohamed Fayad and Douglas C. Schmidt:
Enterprise application frameworks -- These frameworks address broad application domains (such as telecommunications, avionics, manufacturing, and financial engineering) and are the cornerstone of enterprise business activities. Relative to System infrastructure and Middleware integration frameworks, Enterprise frameworks are expensive to develop and/or purchase. However, Enterprise frameworks can provide a substantial return on investment since they support the development of end-user applications and products directly. In contrast, System infrastructure and Middleware integration frameworks focus largely on internal software development concerns. Although these frameworks are essential to rapidly create high quality software, they typically don't generate substantial revenue for large enterprises. As a result, it's often more cost effective to buy System infrastructure and Middleware integration frameworks rather than build them in-house.
Regardless of their scope, frameworks can also be classified by the techniques used to extend them, which range along a continuum from whitebox frameworks to blackbox frameworks. Whitebox frameworks rely heavily on OO language features like inheritance and dynamic binding to achieve extensibility. Existing functionality is reused and extended by (1) inheriting from framework base classes and (2) overriding pre-defined hook methods using patterns like Template Method. Blackbox frameworks support extensibility by defining interfaces for components that can be plugged into the framework via object composition. Existing functionality is reused by (1) defining components that conform to a particular interface and (2) integrating these components into the framework using patterns like Strategy and Functor.
Whitebox frameworks require application developers to have intimate knowledge of the framework's internal structure. Although whitebox frameworks are widely used, they tend to produce systems that are tightly coupled to the specific details of the framework's inheritance hierarchies. In contrast, blackbox frameworks are structured using object composition and delegation more than inheritance. As a result, blackbox frameworks are generally easier to use and extend than whitebox frameworks. However, blackbox frameworks are more difficult to develop since they require framework developers to define interfaces and hooks that anticipate a wider range of potential use-cases.
RADICORE is not expensive to purchase as it is available for free as open source under the GNU Affero General Public License.
RADICORE is a whitebox framework in that it uses inheritance from an abstract class coupled with the Template Method Pattern so that predefined "hook" methods can be overridden in concrete subclasses. I have found that the proper use of inheritance using abstract classes provides far more reusability than can be obtained from object composition. Service objects such as Controllers, Views and DAOs are pre-written and come supplied in the framework.
The fact that whitebox frameworks require application developers to have intimate knowledge of the framework's internal structure should not be an issue provided that the structure is based on well known design patterns and is properly documented, as shown in Figure 3 and Figure 4.
As for being tightly coupled to the specific details of the framework's inheritance hierarchies, this should not be an issue as RADICORE does not have any deep inheritance hierarchies - every Model class inherits its invariant methods from the same abstract table class.
The article goes on to say:
Frameworks are closely related to other approaches to reuse, including:
- Patterns -- Patterns represent recurring solutions to software development problems within a particular context. Patterns and frameworks both facilitate reuse by capturing successful software development strategies. The primary difference is that frameworks focus on reuse of concrete designs, algorithms, and implementations in a particular programming language. In contrast, patterns focus on reuse of abstract designs and software micro-architectures.
Frameworks can be viewed as a concrete reification of families of design patterns that are targeted for a particular application-domain. Likewise, design patterns can be viewed as more abstract micro-architectural elements of frameworks that document and motivate the semantics of frameworks in an effective way. When patterns are used to structure and document frameworks, nearly every class in the framework plays a well-defined role and collaborates effectively with other classes in the framework.
The particular application-domain which is targeted by RADICORE is any database application which can be used by businesses. These are typically known as enterprise applications as they are used to record and report on the organisation's business activities. These applications are characterised by having HTML forms at the front end, an SQL database at the back end, and software in the middle to handle both the transport of data between the two ends and the processing of any business rules. This pattern is a perfect match for the 3-Tier Architecture which is the foundation on which the RADICORE framework was built. This was later extended to incorporate the Model-View-Controller Design Pattern and, because of my use of an abstract table class, the Template Method Pattern.
- Class libraries -- Frameworks extend the benefits of OO class libraries in the following ways:
- Frameworks define "semi-complete" applications that embody domain-specific object structures and functionality -- Components in a framework work together to provide a generic architectural skeleton for a family of related applications. Complete applications can be composed by inheriting from and/or instantiating framework components. In contrast, class libraries are less domain-specific and provide a smaller scope of reuse. For instance, class library components like classes for Strings, complex numbers, arrays, and bitsets are relatively low-level and ubiquitous across many application domains.
- Frameworks are active and exhibit "inversion of control" at run-time -- Class libraries are typically passive, i.e., they perform their processing by borrowing threads of control from self-directed application objects. In contrast, frameworks are active, i.e., they control the flow of control within an application via event dispatching patterns like Reactor and Observer. The "inversion of control" in the run-time architecture of a framework is often referred to as the Hollywood Principle, i.e., "Don't call us, we'll call you."
In practice, frameworks and class libraries are complementary technologies. For instance, frameworks typically utilize class libraries like the C++ Standard Template Library (STL) internally to simplify the development of the framework. Likewise, application-specific code invoked by framework event handlers can utilize class libraries to perform basic tasks such as string processing, file management, and numerical analysis.
RADICORE is "semi-complete" in that it has its own database and GUI which give it the ability to run your application components. All you have to do is generate your application components first, but even this task is automated by functions within my Data Dictionary using a pre-built series of patterns and templates.
Business-facing enterprise applications differ from public-facing websites in that they have common sets of requirements which can be provided as part of the framework as pre-built and runnable components so that they do not have to be duplicated by the application developer.
Inversion of Control (IoC) is handled by the framework at two levels - in the way that it calls application tasks and amends default behaviour within a task.
- Components -- Components are self-contained instances of abstract data types (ADTs) that can be plugged together to form complete applications. Common examples of components include VBX controls and CORBA Object Services. In terms of OO design, a component is a blackbox that defines a cohesive set of operations, which can be reused based solely upon knowledge of the syntax and semantics of its interface. Compared with frameworks, components are less tightly coupled and can support binary-level reuse. For example, applications can reuse components without having to subclass from existing base classes.
The relationship between frameworks and components is highly synergistic, with neither subordinate to the other. Frameworks can be used to develop components, whereby the component interface provides a Facade for the internal class structure of the framework. Likewise, components can be used as pluggable strategies in blackbox frameworks. In general, frameworks are often used to simplify the development of infrastructure and middleware software, whereas components are often used to simplify the development of end-user application software. Naturally, components are also effective for developing infrastructure and middleware, as well.
The RADICORE framework has several pre-built service components such as Controllers, Views and DAOs which can be used by any Model within any application subsystem. This is because all the components are as loosely coupled as they can possibly be due to the fact that all application data is passed around in a single array instead of as separate elements. This means that the contents of the array can be varied without the ripple effect caused by having to change method signatures when each element is a separate argument.
Internet applications have rendered certain components obsolete - VBX controls have been replaced by HTML controls, and CORBA has been replaced by web services.
The article goes on to say:
When used in conjunction with patterns, class libraries, and components, OO application frameworks can significantly increase software quality and reduce development effort. However, a number of challenges must be addressed in order to employ frameworks effectively. Companies attempting to build or use large-scale reusable framework often fail unless they recognize and resolve challenges such as development effort, learning curve, integratability, maintainability, validation and defect removal, efficiency, and lack of standards, which are outlined below:
In the following list I show how I have addressed each of these challenges.
Development effort -- While developing complex software is hard enough, developing high quality, extensible, and reusable frameworks for complex application domains is even harder. The skills required to produce frameworks successfully often remain locked in the heads of expert developers. One of the goals of this theme issue is to demystify the software process and design principles associated with developing and using frameworks.
The development effort required to build an enterprise framework depends entirely on the experience and skill of the developer. Prior to switching to PHP in 2002 I had worked on numerous enterprise applications for over 20 years, and I had demonstrated my skill in replacing duplicate code with reusable libraries in the early 1980s. I had extended this to build my first framework in COBOL in the mid-1980s, followed by a second version in UNIFACE in the 1990s. These both had similar database designs and similar functionality, so when I started my third version in 2003 all I had to do was build the same database using MySQL and duplicate the same functionality using PHP. It wasn't exactly rocket science.
Although I could increase the amount of reusable code by utilising the capabilities of encapsulation, inheritance and polymorphism, the biggest saving was made by being able to replace screens which had to be individually defined and compiled with HTML forms which could be constructed from templates. An HTML document is not delivered a a compiled binary, it is simply a text file containing HTML tags. As I had become familiar with XSL templates during my work with UNIFACE I decided to stick with this technique for my PHP implementation. I published the results of my work in Using PHP 4's DOM XML functions to create XML files from SQL data and Using PHP 4's Sablotron extension to perform XSL Transformations. Although I started with separate XSL stylesheets for each web page I used my skill to create a small set of reusable XSL stylesheets which could be used to create any web page. This also meant that I could have a single pre-built View object which could generate the HTML page for any task in any application.
My use of a single abstract class which could be inherited by every Model class also paid dividends. As well as being able to implement the Template Method Pattern for every task, the fact that every Model automatically implemented the same methods meant that I could take advantage of polymorphism and use dependency injection to mate a Controller with a Model. This is why my Controllers are pre-built and supplied in the framework instead of having to be hand-crafted by the developer.
The use of reusable XSL stylesheets and reusable Controllers culminated in the creation of a catalog of Transaction Patterns. Unlike design patterns which are nothing but designs which you have to implement yourself, Transaction Patterns can provide you with instant implementations - simply select a database table, select a pattern, press a button, then run the component script which has just been generated.
Learning curve -- Learning to use an OO application framework effectively requires considerable investment of effort. For instance, it often takes 6-12 months become highly productive with a GUI framework like MFC or MacApp, depending on the experience of developers. Typically, hands-on mentoring and training courses are required to teach application developers how to use the framework effectively. Unless the effort required to learn the framework can be amortized over many projects, this investment may not be cost effective. Moreover, the suitability of a framework for a particular application may not be apparent until the learning curve has flattened.
Learning to use a framework depends on how familiar you are with the underlying technologies. RADICORE uses a wide variety of standard technologies:
Every web developer should be familiar with these technologies, so the learning curve should not be that steep.
Integratability -- Application development will be increasingly based on the integration of multiple frameworks (e.g. GUIs, communication systems, databases, etc.) together with class libraries, legacy systems, and existing components. However, many earlier generation frameworks were designed for internal extension rather than for integration with other frameworks developed externally. Integration problems arise at several levels of abstraction, ranging from documentation issues, to the concurrency/distribution architecture, to the event dispatching model. For instance, while inversion of control is an essential feature of a framework, integrating frameworks whose event loops are not designed to interoperate with other frameworks is hard.
Integration with other "frameworks" should not be necessary - the GUI is standard HTML, the network protocol is HTTP, the database protocol is SQL, all the function libraries and class libraries are standard PHP and built into the framework, and there are no legacy systems. In fact, RADICORE should be used as the quickest means to replace those legacy systems. All communication between components is by standard method calls provided by the programming language.
Maintainability -- Application requirements change frequently. Therefore, the requirements of frameworks often change, as well. As frameworks invariably evolve, the applications that use them must evolve with them.Framework maintenance activities include modification and adaptation of the framework. Both modification and adaptation may occur on the functional level (i.e., certain framework functionality does not fully meet developers' requirements), as well as on the non-functional level (which includes more qualitative aspects such as portability or reusability).
Framework maintenance may take different forms, such as adding functionality, removing functionality, and generalization. A deep understanding of the framework components and their interrelationships is essential to perform this task successfully. In some cases, the application developers and/or the end-users must rely entirely on framework developers to maintain the framework.
As well as maintaining the framework since its inception in 2003 I have also been responsible for building and maintaining an enterprise application which uses this framework since 2007. Sometimes a requirement it so unique that it can only be satisfied in application code, but sometimes it can be made generally available by changing something in the framework. The wide use of Template Methods means that a change to the abstract class can be instantly inherited by every Model class, and the introduction of new "hook" methods has zero impact on all existing Models. The fact that all the Controllers and Views are reusable means that changes to a small number of components can have an effect on a large number of user transactions. For example, in 2000 I upgraded all 4,000 HTML forms in my ERP application to have a responsive web interface, but this only required changes to 12 XSL stylesheets and one View component and took just one month.
Validation and defect removal -- Although a well-designed, modular framework can localize the impact of software defects, validating and debugging applications built using frameworks can be tricky for the following reasons:
- Generic components are harder to validate in the abstract -- A well-designed framework component typically abstracts away from application-specific details, which are provided via subclassing, object composition, or template parameterization. While this improves the flexibility and extensibility of the framework, it greatly complicates module testing since the components cannot be validated in isolation from their specific instantiations.
Moreover, it is usually hard to distinguish bugs in the framework from bugs in application code. As with any software development, bugs are introduced into a framework from many possible sources, such as failure to understand the requirements, overly coupled design, or an incorrect implementation. When customizing the components in framework to a particular application, the number of possible error sources will increase.
- Inversion of control and lack of explicit control flow -- Applications written with frameworks can be hard to debug since the framework's "inverted" flow of control oscillates between the application-independent framework infrastructure and the application-specific method callbacks. This increases the difficulty of "single-stepping" through the run-time behavior of a framework within a debugger since the control flow of the application is driven implicitly by callbacks and developers may not understand or have access to the framework code. This is similar to the problems encountered trying to debug a compiler lexical analyser and parser written with LEX and YACC. In these applications, debugging is straightforward when the thread of control is in the user-defined action routines. Once the thread of control returns to the generated DFA skeleton, however, it is hard to trace the program's logic.
As both the framework and any application subsystems are written in PHP then both sets of code are visible using an IDE with a symbolic debugger. The framework code is not hidden while it is being executed, so the developer can easily track the complete execution path, whether it be in the framework or the application, line by line.
Following the flow of control is made easy by the fact that every Model uses an abstract class which is heavily populated with invariant and variable "hook" methods. Any complications caused by object composition and method callbacks are therefore non-existent.
If there is a problem with the HTML output then the developer can trap the XML document to look for errors there as this contains all the information used in the XSL transformation. Alternatively he could use an XSL debugger to track the processing flow through the XSL stylesheet.
Efficiency -- Frameworks enhance extensibility by employing additional levels of indirection. For instance, dynamic binding is commonly used to allow developers to subclass and customize existing interfaces. However, the resulting generality and flexibility often reduce efficiency. For instance, in languages like C++ and Java, the use of dynamic binding makes it impractical to support Concrete Data Types (CDTs), which are often required for time-critical software. The lack of CDTs yields (1) an increase in storage layout (e.g., due to embedded pointers to virtual tables), (2) performance degradation (e.g. due to the additional overhead of invoking a dynamically bound method and the inability to inline small methods), and (3) a lack of flexibility (e.g., due to the inability to place objects in shared memory).
The efficiency of dynamic binding of an abstract class to a concrete class is not an issue today, especially with a language such as PHP running on current hardware.
Lack of standards -- Currently, there are no widely accepted standards for designing, implementing, documenting, and adapting frameworks. Moreover, emerging industry standard frameworks (such as CORBA, DCOM, and Java RMI) currently lack the semantics, features, and interoperability to be truly effective across multiple application domains. Often, vendors use industry standards to sell proprietary software under the guise of open systems. Therefore, it's essential for companies and developers to work with standards organizations and middleware vendors to ensure the emerging specifications support true interoperability and define features that meet their software needs.
I do not believe that there could ever be a set of standards by which every framework should be built. If a framework is built for a specific type of application, such as an enterprise application, instead of being a general-purpose framework for a broader category of application, then it should be built around the technologies which are used by that type of application. Each of these technologies - HTML, CSS, XML, XSL, SQL, HTTP, etc - have their own standards, and the framework should identify how it integrates all these technologies. Each different framework will have its own unique way of doing things, so the notion of a "standard" way to document something which is unique simply does not exist.
As well as the standard functionality which everyone would expect to see in an enterprise application framework RADICORE has been upgraded to include some extra features.
The name RADICORE is derived from two words - RAD, which stands for Rapid Application Development, and CORE, which means that it provides the core or basic processing for any enterprise application.
Every application consists of a number of different components, sometimes hundreds or perhaps even thousands, which perform different operations on the different entities within that application. Every framework, and even those faux frameworks which in reality are nothing but libraries in disguise, should have the ability to generate these components. This ability can be provided in many different ways, with different solutions requiring different amounts of effort and producing different results. Below is a list of articles I found on the internet after searching for CRUD generators:
All these examples have a common theme:
When I look at how much effort is required to produce such primitive results I just thank my lucky stars that I am no longer constrained by other people's lack of imagination and ability. When I claim that RADICORE was designed with Rapid Application Development in mind I mean that development times can be measured with a stopwatch, not a calendar. Starting with nothing more than a table's definition in a database I can import the table's structure into my Data Dictionary, generate the class file, then generate a family of six CRUD forms to maintain the contents of that table in less than 5 minutes without writing a single line of code - no PHP, no HTML, no SQL. This is achieved by doing things differently from all the other faux frameworks:
If you do not believe that so much can be achieved with so little effort the I suggest you take a look at my Videos page, especially Video #1.
When it comes to reusability it should be recognised that the more reusable code you have the less code you have to write, and the less code you have to write to get the job done means that you can get the job done quicker and the more productive you will be. My decades of experience with enterprise applications has allowed me to tell the different between code which is payload and code which is plumbing. I have also moved as much plumbing code as possible into reusable components so that I don't have to keep rewriting that code.
All tasks which run under the RADICORE framework are comprised of the same four objects shown in Figure 3. Note that this arrangement helps me to provide these levels of reusability which in turn means that the effort required to generate application components is much less than is possible in other frameworks, especially the faux frameworks.
It was this level of reusability which helped me to create my first ERP application in only 6 months in 2007. I had already learned that for a database application the best place to start was with a properly normalised database, so a picked a series of database designs which were flexible, powerful, and which provided a lot of options. These came from Len Silverston's Data Model Resource Book which provided sets of database designs for different business areas. I picked the following as an initial set of subsystems which were required by the first client:
After creating each database it was a simple task to use the facilities within the Data Dictionary to create the class files followed by the basic tasks, after which I could concentrate on populating the "hook" methods with the business logic. I had the first working prototype completed within 6 months, which meant that developing each of the above subsystems took an average of one man-month. Could YOUR framework match that?
As well as being able to create bespoke application subsystems, I have actually used the RADICORE framework to create an ERP application as a package which can be used by many different customers, thereby reducing the cost to each customer. The first version with six additional subsystems went live in 2008 under the name TRANSIX, while the second enhanced version with several more subsystems was released in 2014 under the name GM-X.
My previous experience with package software taught me that it is impossible to provide a common solution which covers 100% of the requirements of each user. Every organisation has its own way of doing things, so a degree of customisation is almost always required. That is why I built into the framework, and hence every application built using the framework, the ability to "drop in" customisations without affecting the package's core code. It is therefore easy to customise individual screens, and even to customise the business logic which is executed at runtime. If necessary it is even easy to create a bespoke subsystem with its own database. Because every subsystem runs under the "umbrella" of the framework they appear to the end-user as being seamlessly integrated instead of being a collection of stand-alone applications.
In order to qualify for the title of "framework" a product should have the following attributes:
If the product you are using does not have all of these attributes then does it really deserve the title of "framework"?
There is something else which identifies whether a piece of software is a library or a framework, and that is how you install it. If you use Composer then it is a library. This is what it says in the Composer website:
Composer is a tool for dependency management in PHP. It allows you to declare the libraries your project depends on and it will manage (install/update) them for you.
This clearly says that it is used to install the libraries which are used by your project and not to install the project itself. An enterprise framework such as RADICORE is a semi-complete application/project, so cannot be installed using Composer.
A proper framework should greatly reduce, or even eliminate altogether, the amount of code that needs to be written to perform standard "plumbing" tasks, thus leaving the developer with more time to spend on the valuable "payload". One of the early users of the RADICORE framework was amazed at how much code he did not have to write.
This made one of the early users of my framework to to say "I was amazed at how much code I did not have to write!"
If you have something which calls itself a framework, but it does not handle all of this "plumbing" automatically, and you have to write a lot of code yourself, then it is not a true framework but a simple library.
Here endeth the lesson. Don't applaud, just throw money.
Here are some newsgroup posts which criticise my point of view:
| 1st May 2024 | Added Definition from Ralph E. Johnson & Brian Foote. |
| 01 Jan 2023 | Added Why use a Framework?
Added Why can RADICORE be called an Enterprise Application Framework? Added Additional functionality Moved 1st version in COBOL to a separate article. Moved 2nd version in UNIFACE to a separate article. Moved 3rd version in PHP to a separate article. |
| 10 Jan 2022 |
Added 1st version in COBOL
Added 2nd version in UNIFACE Added 3rd version in PHP |
| 11 Jun 2020 | Added definition from Douglas C. Schmidt. |
| 09 May 2020 | Added definition from the Gang of Four. |
| 28 Apr 2020 | Added What is a Framework? with a reference to a definition from Craig Larman. |
| 16 Apr 2020 | Added The meaning of "Inversion of Control (IoC)" |