2nd August 2003
Amended 1st May 2024
As of 10th April 2006 the software discussed in this article is available as open source and can be downloaded from www.radicore.org
With every programming language I have worked in it has become normal practice, after having developed an initial series of programs, to identify a common structure to which all subsequent programs should be built. This may take some time as it involves a bit of trial and error in playing with the different ways in which a task can be achieved in order to find the methodology that gives the most advantages in the long term. Eventually this development infrastructure/environment should contain the following:-
The list can be extended even further, but that will do as a starting point.
The PHP development environment that I have devised was created by taking a set of sample programs which I had assembled for a previous language and rewriting them in PHP. These sample programs were used as patterns or templates for all other programs in my applications as they represented all the combinations of structure and behaviour that I had encountered. To build a new component all I had to do was identify the right template, then specify which database tables(s) and columns I wished to show on the screen for the new component. Each database table was accessed via its own separate service component which contained all the business rules associated with that table plus the code to communicate with the database. As each user screen accessed each database table by its own service component it meant that business logic was shared and not duplicated. Both user screens and service components used shared code in the form of 'include' files, so it was possible to update the shared library and have the changes automatically picked up by the various components.
From the outset my aim was to produce an environment with the following characteristics:-
What I actually produced is as follows:-
Interestingly enough my decision to have all HTML output generated through XSL transformations instead of directly by PHP code actually paid enormous dividends by producing a great deal more reusable code than I had originally anticipated. I started by creating a script which performed an operation on a database table then wrote a second script to perform the same operation on a different table. I then compared the two scripts to see what was duplicated and could therefore be put into a sharable file, and what was different and which would have to remain in a script of its own. By careful engineering of the code I ended up with the situation where there were basically only two differences:
I ended up with three types of PHP script in my presentation layer:
When building the XSL stylesheets I came across common code which I was able to move into separate files as XSL templates (subroutines). These templates can be accessed by any number of stylesheets using the <xsl:include> command. A later improvement meant that instead of having a separate XSL stylesheet for each screen where the field names and field labels were hard-coded I could use a much smaller number of generic stylesheets and have the list of field names and field labels supplied within the XML document. The type of HTML control to be used for each field is written to the XML document as a series of field attributes, and a standard XSL template uses these attributes to generate the correct HTML code.
Any piece of software can be subdivided into the following areas:
This topic is discussed in greater detail in What is the 3-Tier Architecture?
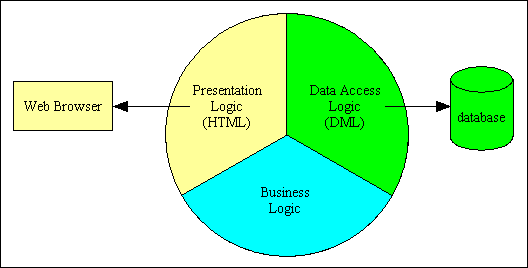
If you put the code which deals with presentation logic (the generation of HTML documents), business logic (the processing of business rules) and data access logic (the generation and execution of DML (SQL) statements) into a single component then what you have is a single tier structure, as shown in Figure 1.
Figure 1 - 1 Tier architecture
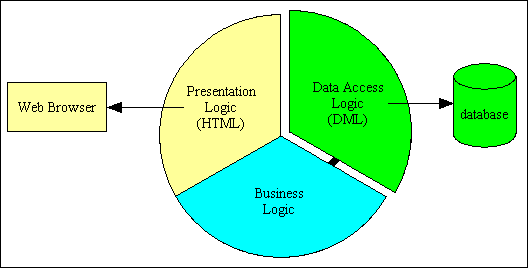
If you split off all the code that handles the communication with the physical database to a separate component then you have a 2 tier architecture, as shown in Figure 2.
Figure 2 - 2 Tier architecture
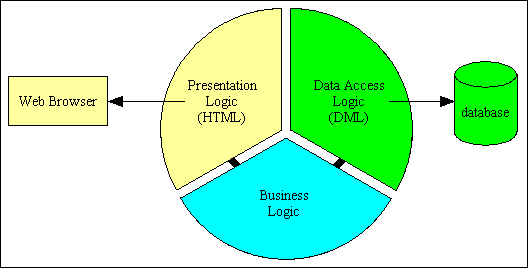
If you go one step further and split the presentation logic from the business logic you have a 3 Tier Architecture, as shown in Figure 3. Note that there is no direct communication between the presentation and data access layers - everything must go through the business layer in the middle.
Figure 3 - 3 Tier Architecture
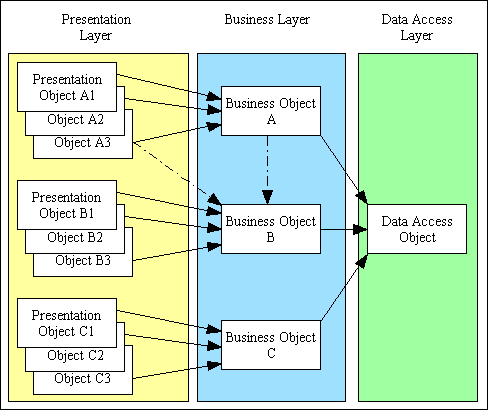
When this architecture is implemented the benefits will become apparent as more code can be shared instead of being duplicated. Several components in the presentation layer can share the same component in the business layer, and all components in the business layer share the same component in the data access layer. This is shown in Figure 4. Note also that a presentation layer component can access more than one business layer component, and a business layer component can access other business layer components.
Figure 4 - 3 Tier Architecture in operation
The big advantage of a 3-tier system is that it is possible to change the contents of any one of the tiers/layers without having to make corresponding changes in any of the others. For example:
You should also notice here that the Business object is only responsible for assembling data in response to a request from the Presentation object. The Business object does not know or care what the Presentation object does with that data - it may build it into a compiled form, an HTML page, a PDF document, a CSV file, an XML document in response to a web service request, or whatever.
By having separate layers with different responsibilities this architecture also makes it possible to use different teams of developers to work on each. That means I can need PHP skills for the business layer, SQL skills for the data access layer, and (X)HTML, CSS and XSL skills for the presentation layer. It may be easier to find developers with skills in one of these areas rather than all three.
The environment which I have created is based on the 3-tier architecture, as shown in Figure 5.
Figure 5 - Environment/Infrastructure Overview
")
Note that each object in the above diagram is a hyperlink which, when clicked, will take you to the relevant component description which is also contained in the following list:
Note that this is proper 3-Tier Architecture, not the pseudo variety as claimed by many who seem to think that the arrangement of web browser, web server and database automatically constitutes a 3 Tier system. It is the construction of the software in the middle that decides whether the system is 1, 2 or 3 Tier. It is only when a system has separate components to deal with the different areas of logic that it can be truly described as 3-tier.
The infrastructure described in this document has the following degrees of separation:-
This is part of 3 Tier Architecture. It contains a separate component script for each transaction or task within the system. This is a simple mechanism which identifies which model, view and controller components to use.
The controller script handles the transaction behaviour.
The database table class (model) identifies the entity or entities which need to be accessed.
The Controller performs operations on the Model in order to change the state of the Model after which it is injected into the View object.
The View object extracts data from the Model, transforms it into another format, usually into HTML, and sends the result back to the client. There will be different view objects for alternative formats such as PDF or CSV.
This is part of 3 Tier Architecture. It contains a separate table class for each database table or business entity. Each table class is a subclass of a generic table class so that it can inherit as much generic code as possible.
All communication with the physical database is handled by the generic table class through a separate DML class.
Primary data validation is handled by the generic table class through a validation class. Secondary data validation is performed by customisable methods within each table class.
This layer also communicates my Workflow Engine in order to determine if a new workflow case needs to be created, and to progress each case through its various stages.
This is part of 3 Tier Architecture. It consists of a one or more DML objects which issue the functions to communicate with the physical database(s). There is a separate DML class for each database engine (MySQL, PostgreSQL, Oracle, SQL Server). This is sometimes referred to as a Data Access Object (DAO).
Not only is it possible within the same transaction to access tables in different databases, it is also possible to access tables through different database engines.
This layer also communicates my AUDIT class in order to record all changes made to an application database in a separate 'audit' database so that they can be reviewed using online enquiry screens.
It was some time after I had developed this infrastructure that I discovered that it also contained an implementation of the MVC design pattern. This is discussed in more detail in The Model-View-Controller (MVC) Design Pattern for PHP.
Figure 6 - The Model-View-Controller structure
")
Note that each object in the above diagram is a hyperlink which, when clicked, will take you to the relevant component description.
A model is an object which directly manages the data, logic and rules of the application. In my infrastructure this is implemented as a series of table classes, one for each table in the database, which inherit a large amount of code from the abstract table class. Each class handles the data validation and business rules for a single database table, but note that all communication with the physical database is routed through a separate DML Object, with a separate DML class for each supported DBMS engine.
A view is some form of visualisation of the state of the model. In my infrastructure I can format and send data to the client in one of three possible formats:
A controller offers facilities to change the state of the model. It accepts input from the user and instructs the model to perform actions based on that input, then updates the View to show the results of those actions.
In my infrastructure this is implemented as a series of component scripts which link to one of a series of transaction pattern (controller) scripts, one for each Transaction Pattern.
When the 3 Tier Architecture is combined with the Model-View-Controller design pattern it produces the structure, which can be referred to as Model-View-Controller-DAO (MVCD), as shown in Figure 7 below:
Figure 7 - MVC and 3 Tier Architecture combined
")
Note that each of the above boxes is a hyperlink which will take you to a detailed description of that component.
An alternative diagram which shows the same information in a different way is shown in Figure 8 below::
Figure 8 - The MVC and 3-Tier architectures combined
")
You should clearly see that these two patterns do not fight each other, all they do is overlap so that a single component in one is split into two components in the other.
A more detailed structure diagram is shown in Figure 5 above.
In his article How to write testable code the author identifies three main categories or classifications that can be used to describe an object:
| Entities | An object whose job is to hold state and associated behavior. The state (data) can be persisted to and retrieved from a database. Examples of this might be Account, Product or User. In my framework each database table has its own Model class. |
| Services | An object which performs an operation. It encapsulates an activity but has no encapsulated state (that is, it is stateless). Examples of Services could include a parser, an authenticator, a validator or a transformer (such as transforming raw data into HTML, CSV or PDF). In my framework all Controllers, Views and DAOs are services. |
| Value objects | An immutable object whose responsibility is mainly holding state but may have some behavior. Examples of Value Objects might be Color, Temperature, Price and Size. PHP does not support value objects, so I do not use them. I have written more on the topic in Value objects are worthless. |
This is also discussed in When to inject: the distinction between newables and injectables.
The components in the RADICORE framework fall into the following categories:
It should also be noted that:
Some of my approaches to infrastructure design are based on experiences which I have had in previous languages. It is encouraging to know that some of my design decisions as just as valid now as they were then. It just goes to show that quality is ageless.
Some designers have the peculiar notion that the complexity of a system is directly proportional to the number of components it contains, therefore they try to pack as many functions as possible into a single component. In order to maintain the contents of a typical database table it is usual to provide the following functionality:
It is possible to put all this functionality into a single component, but the end result is a very large, very complex component. If this approach is duplicated throughout the entire system the end result is a collection of very large, very complex components. In my experience the size of a component is directly proportional to the amount of effort needed to maintain it, so smaller is better.
The alternative approach, one which I first found to be successful when COBOL was my primary language and which was just as successful when I switched to UNIFACE, is to provide each of these facilities in a separate component. This may produce a large number of components, but at least they are small and simple. The arguments for the 'small and simple' approach against the 'large and complex' are explored in more detail in my article Component Design - Large and Complex vs. Small and Simple.
When I read that when designing components for web pages the 'small and simple' approach was preferred over the 'large and complex' this did not pose a problem for me as this has been my design philosophy for 20 years.
Now when I want to write software to maintain the contents of a typical database table I build a 'family' of small components where each one performs just one of the previously mentioned functions. This produces a family of components (sometimes referred to as forms or screens) with the structure shown in Figure 9. Each of these components has its own Transaction Pattern (Controller) script. This also made it much easier to allow the Role Based Access Control (RBAC) mechanism in my framework to grant or restrict access to individual members of each family, otherwise it would require more complex code within a composite/compound component.
Figure 9 - A typical Family of Forms
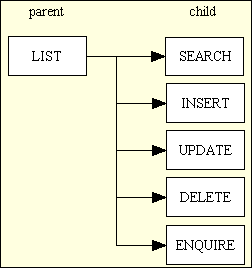
Note that all the boxes in the above diagram are hyperlinks which will take you to a description of that component.
In this structure the LIST (parent) component is the only one that is available on a menu button - all the other child components can only be selected from a navigation button within a suitable parent component. In most cases the child component will need the primary key of an occurrence in the parent component before it can load any data on which it is supposed to act. In this case the required occurrence in the parent screen must be marked as selected using the relevant checkbox before the hyperlink or control button for the child component is pressed.
Another difference between these components is that the LIST component shows multiple rows of details, one occurrence per row, whereas the others will show the details for a single occurrence. As the layout for the SEARCH, INSERT, UPDATE, DELETE and ENQUIRE screens is extremely similar I have managed to provide for their construction with a single XSL stylesheet. This means that for each database table I only need 2 XSL files, as shown in Figure 10.
Figure 10 - XSL files required for a family of forms
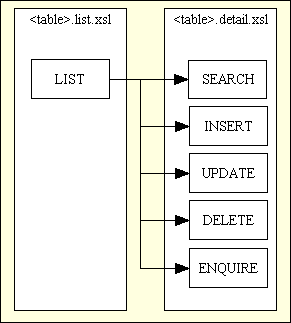
This is made possible as one of the parameters used in the XSL transformation process is $mode. This is used within the XSL stylesheet to determine if each field can be input/amended by the user or should be display only.
In my original infrastructure each database table required its own version of the list.xsl and detail.xsl files as the table, field names and field labels had to be hard-coded inside them, but I have since enhanced my XSL library so that a small number of generic stylesheets can be used for any number of database tables. This is done by providing the list of field names and field labels which are to appear in the data area of the screen in a separate screen structure file which is then copied into the XML document, as documented in Reusable XSL Stylesheets and Templates and uses updated versions of my std.list1.xsl and std.detail1.xsl stylesheets.
In my long career as a software engineer I have written countless hundreds of components, and many times I have come across the situation where I have been asked to create a new component which is "just like that one, but which works on this set of data". In this situation it is necessary to identify those parts of the original component which can be reused 'as is' and those parts which have to be altered. In order to do this I break down each component into the following areas:
The trick now is to make different templates or patterns based on a particular combination of structure and behaviour so that when you build a component from a template all you have to do is specify the content. No two languages provide the same method of creating reusable templates, so what works in one particular language may be totally impossible in another. With PHP the method I have devised is to produce scripts in two categories - Screen Structure scripts which identify the content and reusable Transaction Pattern (Controller) scripts which deal with the structure and behaviour.
A feature of HTML documents is that the visual presentation of each page can be altered quite easily. By 'visual presentation' I mean any of the following:
Although it is possible to include all style specifications within an HTML document it is not considered to be good practice. The most efficient method is to extract all style specifications and keep them in a separate Cascading Style Sheet (CSS) file or files. In this way it is possible to update the contents of a single CSS file and have that change automatically inherited by all the pages which reference the styles defined within that CSS file. Without the use of a CSS file it would be necessary to update each page individually, which on a large site with many HTML pages could be a long and laborious process.
The term 'cascading' means that an HTML document can actually refer to a series of CSS files. These files will be scanned in the order in which they were defined and their contents merged so that a single specification is the result. In my infrastructure I use several CSS files
Although this infrastructure appears to be quite complex due to the large number of components, each component is responsible for just a small area and is therefore relatively simple. The trick is to know which components have to be created by the developer, which components have already been written and are available for immediate use, and how they all hang together.
This is item (1) in Figure 5.
There is one of these for each task (user transaction) within the application. Each task has an entry on the MNU_TASK table in the MENU database so that it can be identified on the ROLE-TASK table (access control list) and made to appear or disappear on either a menu bar or a navigation bar.
Here is an example of one of these scripts:
<?php $table_id = "person"; // identify the Model $screen = 'person.detail.screen.inc'; // identify the View require 'std.enquire1.inc'; // activate the Controller ?>
As you can see this is a simple script whose purpose is to identify the following:
$table_id identifies the Model part of MVC. This is one of the generated database table classes.$screen identifies the View part of MVC. This is one of the generated screen structure scripts.include identifies the Controller part of MVC. This is one of the pre-written controller scripts.Note that each Controller can work with any Model, but is does not know which one until it is given a value for $table_id at run-time.
Because each task in the application has its own controller script in the file system it can be activated simply by putting the address of that script into the browser's address bar, thus avoiding the need for a front controller. However, you should only ever activate a task using the relevant menu button or navigation button otherwise the framework will disallow it.
The URL which appears in the browser's address bar will be in the format <protocol><domain>/<subsystem>/<table>(<pattern>)<suffix>.php where:
Unlike the Transaction Script pattern from Martin Fowler's Patterns of Enterprise Application Architecture (PoEAA) which contains all the processing in a single script, this script does nothing but identify other components which carry out the relevant processing.
Each script in this category simply specifies the Model and View before handing control over to a particular Controller.
The component script for a transaction is automatically created when that transaction is generated from the Data Dictionary.
Sample scripts for each pattern can be found in the /radicore/default/ directory.
This is item (2) in Figure 5.
This can also be referred to as a Transaction Controller or a Page Controller.
Each controller script contains the code to translate the HTTP request into method calls on its Model class(es). As each Model class contains the same set of common table methods this means that any Controller can be reused with any Model. These method calls will then perform the actions which are necessary to complete the request. For example:
Please note that I do not combine these actions into a single Controller as that would require calling the controller with an argument identifying which action it is required to perform. Each Controller is hard-wired to perform only a single action, and its behaviour is only affected depending on whether it was called with the GET or POST method.
There is a separate Controller for each of my Transaction Patterns.
Each script in this category is based on a particular combination of structure and behaviour. The actual content is identified by the Screen Structure script which is set in the calling Component script. This means that one of these Controller scripts may be called by many different Component scripts, as shown in Figure 11.
Figure 11 - Many Component scripts to one Transaction Pattern (Controller) script
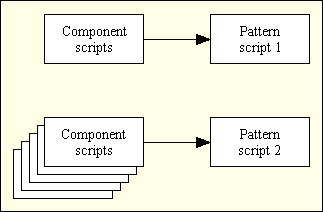
None of these Controller scripts generates any HTML output directly. This is done by the view object which creates an XML document containing all the relevant data, which is then transformed into HTML using a separate XSL stylesheet.
Here is an example of one of my scripts:
<?php // name = std.enquire1.inc // type = enquire1 // This will display a single selected database occurrence using $where // (as supplied from the previous screen) require 'include.general.inc'; // identify mode for xsl file $mode = 'enquire'; // initialise session initSession(); // look for a button being pressed if ($_SERVER['REQUEST_METHOD'] == 'POST') { if (isset($_POST['finish']) or (isset($_POST['finish_x']))) { // cancel this screen, return to previous screen scriptPrevious(); } // if } // if // create a class instance for the main database table require "classes/$table_id.class.inc"; $dbobject = new $table_id; $dbobject->sql_select = &$sql_select; $dbobject->sql_from = &$sql_from; $dbobject->sql_where = &$sql_where; $dbobject->sql_groupby = &$sql_groupby; $dbobject->sql_having = &$sql_having; // check that primary key is complete $dbobject->checkPrimaryKey = TRUE; // define action buttons $act_buttons['finish'] = 'FINISH'; // retrieve profile must have been set by previous screen if (empty($where)) { scriptPrevious('Nothing has been selected yet.'); } // if // get data from the database $fieldarray = $dbobject->getData($where); if ($dbobject->getErrors()) { // some sort of error - return to previous script scriptPrevious($dbobject->getErrors()); } // if // check number of rows returned if ($dbobject->getNumRows() < 1) { scriptPrevious('Nothing retrieved from the database.'); } // if $fieldarray = $dbobject->getExtraData($fieldarray); // build list of objects for output to XML data $xml_objects[]['root'] = &$dbobject; // build XML document and perform XSL transformation $view = new radicore_view($screen_structure); $html = $view->buildXML($xml_objects, $errors, $message); echo $html; ?>
Please note the following points:
'<table_id>.class.inc', so all the Component script need do is supply a value for $table_id and the Controller script can create an object from that class.checkPrimaryKey to TRUE I will trigger the code to check that the $where string contains values for all fields which make up the primary key for this database table. The primary key details are specified in the $fieldspec array.fieldname=fieldvalue pairs. Note that while the default query which is generated will be SELECT * FROM $this->tablename [WHERE ...] this query can be customised to anything which is valid SQL. This includes JOINs to other tables, UNIONS, subqueries, Common Table Expressions, et cetera.$sql_??? variables.noedit will cause a field to be read-only, while nodisplay will cause the field to be excluded from the HTML output altogether.Here is a brief explanation of my user-defined functions which are contained within file include.inc:
initSession() - carries out all processing required when a script starts. This includes reading the session data to obtain the contents of the variable $where which contains any selection criteria passed down from the previous script.scriptPrevious() - will return processing to the previous script with an optional error message. Note that this is not the same as pressing the browser's back button.array2where() - transforms an associative array into a string which can be used as the WHERE clause in an SQL SELECT statement. The first parameter is the array, the optional second parameter identifies the subset of fields to be included.$view->buildXML() - takes the $xml_objects array and transfers all the data to an XML document, after which it will perform the XSL Transformation process using the XSL stylesheet which was specified in the screen structure script to produce the HTML output.You should notice that the above script does not contain any hard-coded database, table or field names, therefore it can be used for any database table within the system. The points to consider are:
$table variable which is set by the component script.$object.fieldname=fieldvalue pairs. This is extracted by the view object and transferred to the XML document in an equivalent fieldname=fieldvalue format.I have some controller scripts which work on more than one database object, such as when dealing with a parent-child relationship or a many-to-many relationship, but the principles are exactly the same.
This is item (4) in Figure 5.
This is an abstract class which is based on the ideas outlined in Using PHP Objects to access your Database Tables (Part 1) and (Part 2). It is called an 'abstract' class as it cannot be instantiated into an object due to missing information which is identified in the common table properties. This missing information is not supplied until a 'concrete' Model subclass is instantiated into an object. This class contains a set of common table methods which support the standard CRUD operations which operate on any database table in the application. These methods and properties are automatically inherited by every concrete subclass. Every public method called by a Controller on a Model is an instance of the Template Method Pattern which means that it executes a pre-defined sequence of steps in various sub-methods. Some of these sub-methods contain invariant/fixed code while others, which are initially empty in the abstract class, are variable/customisable and can be declared in the subclass in order to execute additional code which is specific to that subclass.
| Methods called externally | Methods called internally | UML diagram |
|---|---|---|
| $object->insertRecord($_POST) | $fieldarray = $this->pre_insertRecord($fieldarray); if (empty($this->errors) { $fieldarray = $this->validateInsert($fieldarray); } if (empty($this->errors) { $fieldarray = $this->commonValidation($fieldarray); } if (empty($this->errors) { $fieldarray = $this->dml_insertRecord($fieldarray); $fieldarray = $this->post_insertRecord($fieldarray); } return $fieldarray; |
ADD1 Pattern |
| $object->updateRecord($_POST) | $fieldarray = $this->pre_updateRecord(fieldarray); if (empty($this->errors) { $fieldarray = $this->validateUpdate($fieldarray); } if (empty($this->errors) { $fieldarray = $this->commonValidation($fieldarray); } if (empty($this->errors) { $fieldarray = $this->dml_updateRecord($fieldarray); $fieldarray = $this->post_updateRecord($fieldarray); } return $fieldarray; |
UPDATE1 Pattern |
| $object->deleteRecord($_POST) | $fieldarray = $this->pre_deleteRecord(fieldarray); if (empty($this->errors) { $fieldarray = $this->validateDelete($fieldarray); } if (empty($this->errors) { $fieldarray = $this->dml_deleteRecord($fieldarray); $fieldarray = $this->post_deleteRecord($fieldarray); } return $fieldarray; |
DELETE1 Pattern |
| $object->getData($where) | $where = $this->pre_getData($where); $fieldarray = $this->dml_getData($where); $fieldarray = $this->post_getData($fieldarray); return $fieldarray; |
ENQUIRE1 Pattern |
Here the methods called externally are the ones which are called from the Controller while the methods called internally are called only from within the abstract table class which is inherited by every Model. Each external method then acts as a wrapper for a group of internal methods.
Notice that before and after each database operation, which has the "dml_" prefix, there are pairs of "pre_" and "post_" methods. These will contain calls to "hook" methods which have the following format:
function _cm_whatever ($fieldarray) // interrupt standard processing with custom code // if anything is placed in $this->errors the operation will be terminated. { // customisable code goes here return $fieldarray; } // _cm_whatever
Although these methods are defined in the abstract class and called in specific places in the processing flow they have absolutely no effect as all they do is return the input argument $fieldarray untouched. They are designed to be overridden when necessary in a concrete subclass in order to replace the default behaviour (which is to do nothing) with custom logic which is specific to that subclass. This is how I implemented the Template Method Pattern.
Please note the following:
$_POST array. This means that none of the calling code has to mention any columns by their names as this would make the calling code tightly coupled when it should be loosely coupled.load(), validate() and store() as it would be possible to change a column's value after the validate() and before the store(), thus allowing the possibility of invalid data to be written to the database. As these operations always have to be processed in the same sequence I perform them in a wrapper method so that the sequence cannot be interrupted. As well being more efficient by reducing the number of calls, this approach also enables the contents of the wrapper to be modified in the future, such as by adding a new "hook" method, without having to amend the wrapper's API.validate() method as the requirements for the INSERT, UPDATE and DELETE operations are completely different.
store() method as the requirements for the INSERT, UPDATE and DELETE operations are completely different.dml_" prefix do not actually communicate with the database themselves, instead they pass control to a separate Data Access Object where there is a separate version for each supported DBMS.dml_" prefix fail when the generated SQL query is executed then the entire script is aborted. Relevant details will be written to the application's error log as well as being emailed to the system administrator.dml_??? method to be skipped, and the Controller will perform a rollback() instead of a commit() for the current database transaction.getData($where) method as the $where string can contain any combination of selection criteria without the need for separate finder methods. This may return any number of rows. If multiple rows are expected the pagination limits can be controlled by the $rows_per_page and $pageno variables.In order to turn the abstract class into a concrete class the class constructor will execute code to fill the empty common table properties with data. These properties hold metadata, not application data. This metadata is supplied in a separate <tablename>.dict.inc file which is exported from the Data Dictionary.
| $this->dbname | This value is defined in the class constructor. This allows the application to access tables in more than one database. It is standard practice in the RADICORE framework to have a separate database for each subsystem. |
| $this->tablename | This value is defined in the class constructor and is unique within the database. |
| $this->fieldspec | The identifies the columns (fields) which exist in this table and their specifications (type, size, etc). |
| $this->primary_key | This identifies the column(s) which form the primary key. Note that this may be a compound key with more than one column. Although some modern databases allow it, it is standard practice within the RADICORE framework to disallow changes to the primary key. This is why surrogate or technical keys were invented. |
| $this->unique_keys | A table may have zero or more additional unique keys. These are also known as candidate keys as they could be considered as candidates for the role of primary key. Unlike the primary key these candidate keys may contain nullable columns and their values may be changed at runtime. |
| $this->parent_relations | This has a separate entry for each table which is the parent in a parent-child relationship with this table. This also maps foreign keys on this table to the primary key of the parent table. This array can have zero or more entries. |
| $this->child_relations | This has a separate entry for each table which is the child in a parent-child relationship with this table. This also maps the primary key on this table to the foreign key of the child table. This array can have zero or more entries. |
| $this->fieldarray | This holds all application data, usually the contents of the $_POST array, but it could also contain rows of data fetched from a database. It can either be an associative array for a single row or an indexed array of associative arrays for multiple rows. This removes the restriction of only being able to deal with one row at a time, and only being able to deal with the columns for a single table. This also avoids the need to have separate getters and setters for each individual column as this would promote tight coupling which is supposed to be a Bad Thing ™. |
Note that there is not a separate class property for each data column in the table. As the data which comes into a PHP program, either from the user interface or the database, is always presented as an array I do not see any need to insert additional code to split each array into its component parts. This is why I use a standard $fieldarray argument for all application data. This produces maximum flexibility with loose coupling which is far better than the alternative, which is tight coupling.
This is item (3) in Figure 5.
Each database table (or business entity) is represented by its own class which extends (is a subclass of) the generic table class. This contains a mixture of invariant methods containing default code plus a selection of "hook" methods which can be copied into each subclass and populated with custom code in order to override the default behaviour.
This component is an implementation of the Table Module pattern from Martin Fowler's Patterns of Enterprise Application Architecture (PoEAA). It also serves as the Model in the Model-View-Controller design pattern.
The class file for each database table does not have to be generated by hand - with the introduction of A Data Dictionary for PHP Applications it is possible to import the table structures directly from the database's INFORMATION SCHEMA into the data dictionary, then to export those structures into files which can be accessed directly by the application code.
When the table class file is initially generated it contains only a small amount of code, as shown in the following example:
<?php require_once 'std.table.class.inc'; class #tablename# extends Default_Table { // **************************************************************************** // class constructor // **************************************************************************** function __construct () { // save directory name of current script $this->dirname = dirname(__file__); $this->dbname = '#dbname#'; $this->tablename = '#tablename#'; // call this method to get original field specifications // (note that they may be modified at runtime) $this->fieldspec = $this->loadFieldSpec(); } // __construct // **************************************************************************** } // end class // **************************************************************************** ?>
The loadFieldSpec() method will load the contents of a separate table structure file into the common table properties which were defined in the abstract table class.
Note that this class can deal with any number of database rows - I do not have one version to deal with a single row and a second version to deal with a collection of rows.
Note that none of these classes produces output in any particular format, such as HTML, PDF, CSV or whatever. All application data within each table object is held in a single untyped array called $fieldarray, and this array is not transformed into another format until it is processed by an external object. The actual formatting is performed by a dedicated View component using whatever raw data is provided by the Model.
Some people ask the question Where is the code?
when they notice that the generated table class contains nothing but a constructor but can still be used to perform all the CRUD operations on that table. They fail to notice the use of the word extends which indicates that this concrete table class inherits all the standard code from the abstract table class. The only code which needs to be added to this class is custom code which can be inserted into any of the pre-defined "hook" methods.
This is item (5) in Figure 5.
The generic validation class handles primary validation (sometimes referred to as declarative checking) of all user input. It compares the contents of the input array ($fieldarray) with the contents of the $fieldspec array to check that the input data for each field conforms to that field's specifications. It puts any error messages in the current object's $errors array. If this validation was not performed any attempt to write invalid data to the database would produce an SQL error and cause the program to terminate.
This class has two public methods - validateInsertPrimary($fieldarray, $fieldspec) and validateUpdatePrimary($fieldarray, $fieldspec).
The input array (usually the $_POST array or its equivalent) is an array of fieldname=fieldvalue pairs where every value is a string.
The $fieldspec array is an associative array of fieldname=fieldspec pairs. The fieldspec portion is another associative array of keyword=value pairs. This is obtained by reading the contents of the table structure file which is filled with information which was initially extracted from the database's INFORMATION SCHEMA and imported into the Data Dictionary before being exported as a PHP script.
The $errors array is an array of fieldname=errormsg pairs. It can therefore contain error messages for any number of fields.
Primary validation is limited to the following checks:
email_address which causes the string to be checked against the relevant pattern.file which causes a check to ensure that a file with that name exists.Secondary validation, such as comparing the contents of one field against the contents of another, must be defined within the individual table subclass using the empty classes provided in the superclass.
It is also possible to supplement the generic validation with the addition of plug-ins, as described in Extending the Validation class.
This is item (6) in Figure 5.
This is the only object in the system which carries out any communication with the physical database. It receives requests from the Generic Table class from which it generates the appropriate DML (Data Manipulation Language) or SQL (Structured Query Language) commands. It then executes these commands by calling the relevant API for the database in question. It does not have a separate version for each table, it has a single version which can handle any table within the database. As it exists in the Data Access layer it can also be referred to as the Data Access Object (DAO).
There is a separate class for each database engine as each engine has its own set of APIs. This design also allows me to isolate and deal with any differences in syntax between the various engines. The name of the class file is in the format dml.???.class.inc where '???' can be MySQL, PostgreSQL, Oracle, SQL Server or whatever. The CONFIG.INC file identifies which database engine is to be used for which database. Although it is usual to have all the databases within a single server instance, it is also possible to have those databases spread across multiple servers on different IP addresses, or even different database engines. It is possible to switch from one database engine to another simply by changing the value in the CONFIG.INC file.
This class is based on the ideas outlined in Using PHP Objects to access your Database Tables (Part 1) and (Part 2). Some of the methods it contains are as follows:
$fieldarray (usually the $_POST array). A check is made before the INSERT to ensure that the primary key and any candidate keys are currently unused.$newarray (usually the $_POST array). This is first compared with $oldarray (the current database values) so that only those fields which have changed are included in the DML statement. The identity of the primary key for use in the WHERE clause is extracted using the contents of the $fieldspec array. If any candidate key has changed it is first checked for uniqueness.$fieldarray. The identity of the primary key for use in the WHERE clause is extracted using the contents of the $fieldspec array.Note that within a single transaction it is possible to access tables in more than one database and through more than one database engine.
This is item (7) in Figure 5.
It uses as its input the contents of the screen structure script and all the database table objects which were accessed by the controller script.
The screen structure script identifies which XSL stylesheet to use for the HTML output, and a list of field names which need to be displayed in the data area.
The processing steps are as follows:
The HTML output is the text file which is sent back to the client's web browser. This is rendered into a viewable page with the assistance of one or more CSS files which are the recommended way of specifying a standard style in a group of HTML documents.
There are different view objects for creating the output in different formats, such as PDF or CSV.
This is item (8) in Figure 5.
These are simple scripts which do nothing but identify the view or content for the output screen. Each one identifies the name of an XSL stylesheet and a list of table names, field names and field labels that will be used during the XSL transformation process to produce the HTML output.
The default script for a transaction is automatically created when that transaction is generated from the Data Dictionary.
Sample scripts for each pattern can be found in the /radicore/default/screens/en/ directory with the name <pattern>.screen.inc.
Scripts for each subsystem can be found in the /radicore/<subsystem>/screens/<language>/ directory. The default value for <language> is 'en' (English), but other language codes can be used - refer to Internationalisation and the Radicore Development Infrastructure for details.
Although the parent LIST screen in Figure 9 will require its own Screen Structure file, all the CHILD screens can share the same one as they all use the same structure. The differences in how the fields are displayed for each of the child components is handled by a combination of the $mode parameter within the Transaction Pattern (Controller) script (insert, update, delete, enquire) and individual field attributes within the XML document. These attributes can be specified within the $fieldspec array for that table class, or can be supplied at runtime through custom code.
Here is a sample file:
<?php // this identifies which XSL stylesheet to use $structure['xsl_file'] = 'std.detail1.xsl'; // this identifies which XML data is to go into which XSL zone $structure['tables']['main'] = 'person'; // this specifies the width of each column $structure['main']['columns'][] = array('width' => 150); $structure['main']['columns'][] = array('width' => '*'); // the following may also be used $structure['main']['columns'][] = array('class' => 'classname'); // this identifies the label and field which is to be displayed in each row $structure['main']['fields'][] = array('person_id' => 'ID'); $structure['main']['fields'][] = array('first_name' => 'First Name'); $structure['main']['fields'][] = array('last_name' => 'Last Name'); $structure['main']['fields'][] = array('initials' => 'Initials'); $structure['main']['fields'][] = array('nat_ins_no' => 'Nat. Ins. No.'); $structure['main']['fields'][] = array('pers_type_id' => 'Person Type'); $structure['main']['fields'][] = array('star_sign' => 'Star Sign'); $structure['main']['fields'][] = array('email_addr' => 'E-mail'); $structure['main']['fields'][] = array('value1' => 'Value 1'); $structure['main']['fields'][] = array('value2' => 'Value 2'); $structure['main']['fields'][] = array('start_date' => 'Start Date'); $structure['main']['fields'][] = array('end_date' => 'End Date'); $structure['main']['fields'][] = array('selected' => 'Selected'); ?>
In this example there is a single data zone called main which is linked with an object called person. Some screens have two or more zones which are linked to different objects. At runtime the fields will be extracted from each object and displayed in the relevant zone. Note that a field must exist both within the object and within the screen structure file in order for it to be displayed.
The name of this file is provided by the Component script in the $screen variable. It is read in by the view object and its contents are added to the XML document to appear something like this:
<root>
......
<structure>
<main id="person">
<columns>
<column width="150"/>
<column width="*"/>
</columns>
<row>
<cell label="ID"/>
<cell field="person_id" />
</row>
<row>
<cell label="First Name"/>
<cell field="first_name"/>
</row>
<row>
<cell label="Last Name"/>
<cell field="last_name"/>
</row>
<row>
<cell label="Initials"/>
<cell field="initials"/>
</row>
....
<row>
<cell label="Start Date"/>
<cell field="start_date"/>
</row>
<row>
<cell label="End Date"/>
<cell field="end_date"/>
</row>
</main>
</structure>
</root>
Several different layouts are now available for displaying user data. For more details on how these can be specified please refer to XSL Structure files in The Model-View-Controller (MVC) Design Pattern for PHP.
As the screen structure file is loaded into memory at the start of each script but not used until the very end, you have the opportunity to make dynamic amendments to the structure before it is used to create and display the HTML output. This is explained in the following links:
This is item (9) in Figure 5.
XML (Extensible Markup Language) is a simple but flexible text format. It is based on an open standard which is maintained by the World Wide Web Consortium. It is used in this infrastructure to provide the XSL transformation process with all the data it needs to produce the HTML output.
The XML document is generated automatically at runtime by the view object. The technique which is used to create this file in PHP 4 is described in Using PHP 4's DOM XML functions to create XML documents from SQL data. For PHP 5 and above please refer to Using PHP 5's DOM functions to create XML documents from SQL data instead.
Each XML document can contain any of the following data:
This is item (10) in Figure 5.
Each component requires an XSL stylesheet in order to transform the data in the XML document into HTML output. In an earlier version of this infrastructure I used different stylesheets for each database table which had the table names, field names and field labels all hard-coded, but I have subsequently found a way to use a smaller number (twelve, to be exact) of generic stylesheets. Instead of having the field details hard-coded within the stylesheet I am now able to extract that information from within the XML document using information supplied in a Screen Structure script. This is is documented in Reusable XSL Stylesheets and Templates.
Although my whole web application uses no more than twelve generic stylesheets there is still some code which is needed in more than one stylesheet. This code has been extracted and placed in a library of XSL templates which can be incorporated into any stylesheet at runtime by means of an <xsl:include> command. This is, in effect, a library of standard XSL subroutines.
Using the components in Figure 9 as an example I would use a generic LIST stylesheet for the parent component and a generic DETAIL stylesheet for all the child components. Variations in how the individual fields are displayed within the various child components is handled primarily by the $mode variable which is passed as a parameter during the XSL transformation process. This is used as follows:
$mode = 'input' or 'search' then all fields are editable.$mode = 'read' or 'delete' then all fields are non-editable.$mode = 'update' then primary key fields are non-editable.$mode = 'search' then any boolean fields are given a third option to emulate a tri-state checkbox (yes, no, undefined).In addition to the $mode parameter the handling of individual fields can be affected by specific attributes in the XML document. These can either be set into the $fieldspec array or altered at runtime using custom code.
noedit attribute will make the field non-editable.nodisplay attribute will make the field invisible.The type of HTML control (textbox, dropdown, radio group, etc) to be used for each field in the HTML output is completely dynamic in nature. This is a 3 stage process:
This is item (11) in Figure 5.
This process will take the contents of an XML document and transform it to another document (in this case an HTML document) using rules contained within an XSL stylesheet. These are all open standards which are supervised by the World Wide Web Consortium.
It is possible to send both the XML and XSL files to the client and have the transformation performed within the client's browser (client-side transformation), but this is unreliable due to the different levels (sometimes non-existent) of XML/XSL support in different browsers. It is much safer to perform the transformation in a single place (the web server) where the software is under the control of the web developer. This is known as a server-side transformation.
The technique which I use to perform XSL transformations in PHP 4 is described in Using PHP 4's Sablotron extension to perform XSL Transformations. For PHP 5 and above please refer to Using PHP 5's XSL extension to perform XSL Transformations instead.
This is item (12) in Figure 5.
This is the document which is sent back to the client's browser is response to the request. Its content should conform to the HTML 5 specification which is supervised by the Web Hypertext Application Technology Working Group.
In an effort to make my output viewable on as many web browsers as possible I stick to the following guidelines:
This is item (13) in Figure 5.
These are Cascading Style Sheets which hold all the styling information (fonts, colours, sizes, positioning, etc) for all HTML documents produced by the application. The tags within each HTML document refer to a style by a class name, and the specifications for each of these classes is held within a CSS file. In this way it becomes possible to change the style specifications for any tag in all documents simply by changing the specifications within a single CSS file.
The following CSS files are available:
This is item (14) in Figure 5.
This class is responsible for detecting all database changes (INSERTs, UPDATEs and DELETEs) and recording them in a separate 'audit' database so that they can be reviewed using online enquiry screens. This is documented in Creating an Audit Log with an online viewing facility.
The only additional code required in any database table class is the setting of a class variable called $audit_logging. By default this is TRUE (the table will be logged) but it can be set to FALSE to disable logging.
This is item (15) in Figure 5.
Sometimes when a particular task is performed, such as 'Take Customer Order', this has to be followed by a series of other tasks in a particular sequence such as 'Charge Customer', 'Pack Order' and 'Ship Order'. Without a Workflow Engine these subsequent tasks must be selected and processed manually, which is where mistakes and inefficiencies can arise.
The purpose of a Workflow System is to manage these tasks in a controlled fashion. This system should have the following components:
The Workflow Engine which I have created as an extension to this development infrastructure is documented in An activity based Workflow Engine for PHP. The engine is activated from within my generic table class therefore no additional programmer coding is required.
Since a major motivation for object-oriented programming is software reuse, it should follow that the effective use of its features can be assessed by the volume of reusable code it produces. When creating an application which contains many components you should be able to compare the amount of code that you have to write with the amount of code that you don't have to write, where the latter is supplied in pre-written and reusable components that can be shared. If you find yourself writing code that has already been written then you are violating the Don't Repeat Yourself (DRY) principle. A library of reusable components provides the following advantages:
This framework contains the following reusable components:
The RADICORE framework is not just a collection of library functions which need to be called by the developer, it is a true framework as it implements the Hollywood Principle (don't call us, we'll call you). The framework itself consists of the following subsystems:
The framework is a modular system which is comprised of a number of integrated subsystems, each of which has its own database, its own directory structure in the file system, and its own entries in the framework database. New application subsystems can be added at any time by following these steps:
An idea of the amount of reusability when creating a typical family of forms for a database table can be shown in figure 12:
Figure 12 - Levels of Reusability
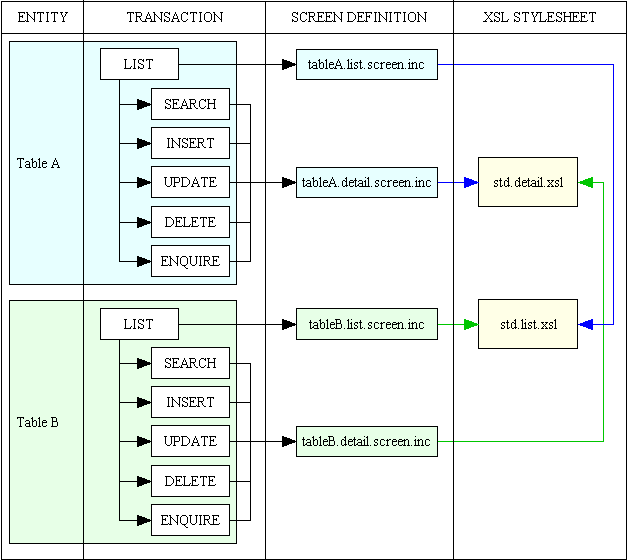
This shows the following:
I have spent 20+ years working for software houses where the task has been to develop many different applications for many different customers in a swift and cost-effective manner. To be truly reusable an infrastructure should not only work for different components within the same application but for different applications entirely. This offers two advantages:
I have witnessed at first hand the advantages of being able to use such infrastructures as I have used them with two entirely different languages - COBOL and UNIFACE. As I was personally responsible for creating those two infrastructures I had all the relevant experience to create a new one in PHP.
As a final example I have used this framework to build a large ERP application the first version of which was called TRANSIX which went live in 2008, but since 2014 has been extended into a product called the GM-X Application Suite. This is comprised of the following:
More information regarding the levels of reusability which I have achieved can be found in the following:
The advantage of having all this reusable code at your disposal is that you don't have to spend time writing it yourself. This also means that you don't have to spend time in designing the code that you don't have to write, as explained in How much time can be saved.
Some of you may be wondering how exactly I achieved these levels of reusability. The answer is quite simple - I did not follow what were later known as "best practices" for the simple reason that I did not know that they existed. In the previous two decades I had encountered numerous documents called Programming Standards where each organisation, and sometimes each team within that organisation, had its own set of standards. As I gained more and more experience I began to see flaws in each of these documents, which is why I began to create my own version using a mix'n'match approach where I took the ideas I liked, ignored the ideas which I didn't like, and sprinkled in a few ideas of my own. When I came to build my own PHP software I did not start by building an application, I built a framework which would allow me to build any application I wanted. This was based on the frameworks which I had built previously in COBOL and UNIFACE, so I already knew what needed to be done. All I had to do was work out how to do it in this new language.
After reading the PHP online manual, and looking at sample code which I found in some online tutorials and books which I bought, I came to the conclusion that PHP offered the following features, which were not available in my previous languages, which could be used to generate a higher volume of reusable code:
My previous experience with database applications had taught me the following:
Before I started on my new framework I had already made the following decisions:
I decided on the following implementation details:
load(), validate() and store() I had already learned that when a group of functions always has to be executed in the same order that a wise programmer would create a wrapper function for that group so that he could call that group with a single statement instead of a separate statement for each member of that group. These "wrapper methods" are outlined in common table methods.Because of the simple decisions described above I was able, using the facilities available in PHP and my own intellect, to refactor the code to increase the volume of code which I could reuse and therefore decrease the volume of code which I had to write. This refactoring took the following forms:
The end result of all these steps was a large amount of reusable code which is built into the framework and which does not have to be written by the developer:
That is a HUGE amount of code which does not have to be written, but there is a small amount which is left over. However, the fact that every user transaction (task) can be fulfilled by a pre-written Controller and a pre-written View has enabled me to catalog each of the possible combinations in my library of Transaction Patterns. This in turn has made it possible for me to generate the code for a user transaction by using the Select Transaction Pattern and Generate PHP scripts functions which link a Model to a pattern.
What this means is that it is possible to create a new table in your database and generate the transactions to view and maintain the contents of that table in a matter of minutes without writing *ANY* code whatsoever - no PHP, no HTML, no SQL. If you don't believe me then I encourage you to watch this video. If you think that YOUR favourite framework is capable of matching that level of productivity then I dare you to take this challenge.
While the generated tasks will only perform the basic functionality the code to handle the more specific business rules can be added in later using any of the empty "hook" methods which are defined in the abstract class but which can be overridden in each concrete subclass.
You should be able to see that each of the above decisions I took was made with one outcome in mind - to increase the amount of code which could be reused. By increasing the amount of code that you *DON'T* have to write I am decreasing the amount of code that you *DO* have to write, and even the dumbest of programmers should realise that there is nothing smaller than no code at all.
Having an infrastructure with which you can build applications is one thing, but in my long experience I have also found it useful to build utility components which may be of benefit to those applications. This type of component is not specific to any particular application, but may be used in conjunction with any number of different applications. Amongst those I have built are:
These are reasons why I consider some ideas on how to do OOP "properly" to be complete rubbish:
| 01 May 2024 | Added The Path to Reusability. |
| 02 Oct 2023 | Updated Generic (abstract) table class to include common table properties and common table methods. |
| 04 Feb 2023 | Added Object Classification. |
| 30 April 2012 | Added a description for View object. |
| 15 July 2005 | Added a reference to a new article entitled Internationalisation and the Radicore Development Infrastructure. |
| 21 June 2005 | Amended Screen Structure scripts to show the new layouts caused by the provision of more flexible options. |
| 17 June 2005 | Added a reference to a new article entitled A Data Dictionary for PHP Applications. |
| 16 Sep 2004 | Added a reference to a new article entitled An activity based Workflow Engine for PHP. |
| 10 Sep 2004 | Added section Extending this Infrastructure. |
| 10 Aug 2004 | Added better descriptions for the individual components. Moved all the Frequently Asked Questions to a separate document. |
| 03 June 2004 | Added a section on Style which explains the advantages of using Cascading Style Sheets. |
| 02 May 2004 | Added a reference to The Model-View-Controller (MVC) Design Pattern for PHP. |
| 28 Apr 2004 | Added a reference to Reusable XSL Stylesheets and Templates which describes a method which enables me to use a single generic stylesheet for many database tables instead of having a customised stylesheet for each individual database table. |
| 10 Nov 2003 | Created a sample application to demonstrate the techniques described in this document. This is described in A Sample PHP Application. The code can be run on my website here, or can be downloaded here and run locally. |
| 08 Sep 2003 | Split my abstract database class again so that the code which performs generic validation (declarative checks) is now contained within its own class. Refer to Business layer for details. |
| 31 Aug 2003 | Split my abstract database class into two so that the construction and execution of all DML statements is now contained within its own class. Refer to Data Access layer for details. |