Figure 1 - MVC and 3 Tier Architecture combined
")
Recently my RADICORE software received an award for the Best Open Source Rapid Application Development Toolkit 2024 from the Innovation in Business Developer Awards. In this article I shall explain the design decisions that I took in order to create the software that was deemed worthy of this award.
Note that this is the third iteration of a framework which I first developed in COBOL in the 1980s, in UNIFACE in the 1990s, and lastly in PHP in the 2000s. In all cases I was the sole designer, and apart from a few utilities in the COBOL version I was also the sole developer.
The only way for an application development framework to be classed as "rapid" is to provide the ability to assemble application components from a library of pre-written and reusable parts. Every user transaction in an enterprise application is comprised of just four components - a Model, View, Controller and Data Access Object - which are provided by RADICORE as follows:
I am not aware of any other open-source framework which provides anywhere near the same levels of reusability as RADICORE, therefore I conclude that none of them can be as productive as RADICORE.
RADICORE is not a general-purpose framework. For starters it cannot be installed using Composer, the dependency manager for PHP, simply because that is for installing third-party libraries into your application, and RADICORE is not a library it is an application in its own right as discussed in What is a Framework? I develop nothing but database applications for businesses, commonly known as enterprise applications, which are characterised by having electronic forms at the front end, a relational database at the back end, and software in the middle to handle the business rules.
RADICORE is an extensible application which is comprised of several core subsystems, and new application subsystems can be developed as pluggable extensions and then run using the facilities provided by the framework. The components of each application subsystem can be developed using the facilities provided within the Data Dictionary, and those components can then be run using the facilities provided within the Role Based Access Control (RBAC) system. Regardless of the unique requirements of each application subsystem they all require the same set of utilities which can be provided from a single sharable source. Among these utilities are the following:
After logging on the user selects combinations of menu buttons and navigation buttons to run selected application tasks. Note that tasks for which the user has not been granted access will be filtered out of the display, and if they cannot be seen they cannot be selected.
Every enterprise application consists of a database containing a number of tables plus a collection of user transactions (tasks or units of work) to maintain and view the contents of those tables. The first step in the development of an application is to design and build the database, then to build the application components using the following steps:
Note that this process does not require the writing of any code - no PHP, no HTML and no SQL - just the pressing of buttons, and should take no longer than FIVE MINUTES. Primary Validation will be carried out by a standard framework component while Secondary Validation for custom business rules can be added later using any of the available "hook" methods.
When my contemporaries question my claims I point them to my Tutorials page and my Videos page. I then challenge them to beat those figures using a framework of their choice, but so far no-one has even made the attempt.
Every software application requires code. The volume of code is determined by three factors:
It is the availability of reusable code which is the critical factor as the more code you can reuse the less you have to write to get the job done, and the less code you have to write the quicker and more productive you will be. Productivity is the key, but far too many of today's programmers fail to recognise practices which produce the best results. Instead they fill their applications with all the "right" design patterns and "common practices" (which may not actually be the "best" at all) in the vain hope that by copying the code produced by so-called "experts" that they will automatically produce expert-level code. They do not understand that these patterns and practices should only be implemented when appropriate, so they end up with code which violates both the DRY and YAGNI principles, thus becoming inefficient and less productive.
I had an advantage over my contemporaries when I began using PHP in 2002 in that I had been designing and building database applications for the previous 20 years. I had used two different languages - COBOL and UNIFACE - and three different database types - hierarchical, network and relational. This meant that I knew how database worked, and I knew how to write code to access them, so all I had to do was write the necessary code in a different language. This also meant moving away from pre-designed and pre-compiled forms to HTML documents, but that was as easy as falling off a log.
It is rarely possible to start by building reusable modules. You first write code that works, then afterwards you look for repeating patterns which can be turned into reusable modules. Looking for patterns means looking for abstractions and involves a process which I learned later is called programming-by-difference. This means looking for similarities and differences in the code and putting the similarities into reusable modules while keeping the differences in unique modules. This may involve the creation of abstract classes which are inherited multiple times, or objects/functions which are called multiple times.
If, like me, you constantly work in a single domain (such as enterprise applications) and produce multiple applications within that domain it is possible to create an abstract design which provides components which can be reused by any application within that domain. According to Designing Reusable Classes this abstract design is called a framework.
Not all categories of code can be reused, but what are these categories? Here are details from a post created by a person called Selkirk in a Sitepoint newsgroup from years ago:
Circa 1996, I was asked to analyze the development processes of two different development teams.Team A's project had a half a million lines of code, 500 tables, and over a dozen programmers. Team B's project was roughly 1/6 the size.
Over the course of several months, management noticed that team A was roughly twice as productive as team B. One would think that the smaller team would be more productive.
I spent several months analyzing the code from both projects, working on both projects and interviewing programmers. Finally I did an exercise which lead to an epiphany. I counted each line of code in both applications and assigned them to one of a half a dozen categories: Business logic, glue code, user interface code, database code, etc.
If one considers that in these categories, only the business logic code had any real value to the company. It turned out that Team A was spending more time writing the code that added value, while team B was spending more time gluing things together.
Team A had a set of libraries which was suited to the task which they were performing. Team B had a set of much more powerful and much more general purpose libraries.
So, Team A was more productive because the vocabulary that their tools provided spoke "Their problem domain," while team B was always translating. In addition, team A had several patterns and conventions for doing common tasks, while Team B left things up to the individual programmers, so there was much more variation. (especially because their powerful library had so many different ways to do everything.)
Here you should see the following important points:
If you are building a web-based enterprise application, one that requires large numbers of database tables and large numbers of user transactions to maintain and view their contents, then having a toolkit which provides a mechanism for building those transactions from a set of pre-defined patterns would be a good idea. If your application requires Role-Based Access Control (RBAC), and perhaps Audit Logging and Workflows, plus the ability for Rapid Application Development (RAD), then you would struggle to find something better than RADICORE.
Every user transaction follows the same pattern by having an HTML form at the front end, an SQL database at the back end, and software in the middle to deal with the the business rules as well as the movement of data between the two ends. In my experience the most efficient way to deal with this scenario is to utilise the 3-Tier Architecture. Using this architecture with PHP was aided by the fact that with OOP the code is automatically 2-tier by default. When you create a class file with methods you must also have a separate script which instantiates that class into an object so that it can call those methods. The class file then exists in the Business layer (the Model in MVC) and the calling script exists in the Presentation layer (the Controller in MVC).
As I had already built hundreds of user transactions in my previous languages I had become aware of patterns of behaviour and structure in the screen layouts, so I had begun to use templates in my code. I had already experimented with XML and XSL to build HTML documents, so I decided to use both of these technologies in my PHP framework. I achieved this by building a single component which could create an HTML document for any user transaction within the application. This meant that I had separate components to deal with receiving an HTTP request and sending out an HTTP response, which meant that I had accidentally created an implementation of the Model-View-Controller design pattern. This combined architecture is shown in Figure 1 below:
Figure 1 - MVC and 3 Tier Architecture combined
Note that each of the above boxes is a hyperlink which will take you to a detailed description of that component.
Each of the above components is supplied as follows:
As you should be able to see from the above the RADICORE framework allows you to create basic but working transactions in a matter of minutes without having to write any code whatsoever - no PHP, no HTML, no SQL. Custom business logic can be added in later. This means that the developer can spend maximum amounts of time on the important business rules and minimum time on the unimportant (to management) "other code". This equates to an extremely high level of productivity.
It is important to note here that when I began programming with PHP I also had to learn how to utilise its OO capabilities to maximum effect. I first found a definition of OOP which went as follows:
Object Oriented Programming is programming which is oriented around objects, thus taking advantage of Encapsulation, Inheritance and Polymorphism to increase code reuse and decrease code maintenance.
My understanding was that object oriented programming was exactly the same as procedural programming except for the addition of encapsulation, inheritance and polymorphism. They are both designed around the idea of writing imperative statements which are executed in a linear fashion. The commands are the same, it is only the way they are packaged which is different. While both allow the developer to write modular instead of monolithic programs, OOP provides the opportunity to write better modules. In his paper Encapsulation as a First Principle of Object-Oriented Design (PDF) the author Scott L. Bain wrote the following:
OO is routed in those best-practice principles that arose from the wise dons of procedural programming. The three pillars of "good code", namely strong cohesion, loose coupling and the elimination of redundancies, were not discovered by the inventors of OO, but were rather inherited by them (no pun intended).
My first port of call was to read the PHP manual which explained how to create classes, thus taking care of Encapsulation. I read about using the "extends" keyword, thus taking care of Inheritance. I didn't find any useful examples of Polymorphism, so I decided to work on that later. I also found some online resources and purchased a few books. At no point was I made aware of these so-called "best practices", so I did my usual thing of working out which practices worked best for me. I played around with the code trying to find the approach which produced a combination of (a) the best result (b) the least amount of code, and (c) the most reusability. My previous experience with database applications made me aware of the following points:
Smart data structures and dumb code works a lot better than the other way around.
This philosophy was also promoted in Jackson Structured Programming (JSP) which I used as the basis for all my subsequent software designs.
The technique of JSP is to analyze the data structures of the files that a program must read as input and produce as output, and then produce a program design based on those data structures, so that the program control structure handles those data structures in a natural and intuitive way.
In a large ERP application, such as the GM-X Application Suite, which is comprised of a number of subsystems, each subsystem has a unique set of attributes:
Despite the fact that these three areas are completely different for each subsystem, they each have their own patterns and so can be handled using standard reusable code provided by the framework:
It was this collection of facts which influenced my development methodology. The code which I created is described in A Sample PHP Application where it can also be downloaded.
These are the steps I went through to create the code to deal with my first database table..
Figure 2 - A typical Family of Forms
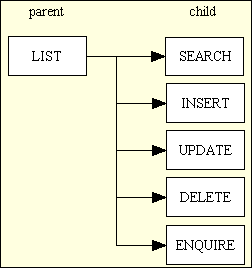
This became the Controller in the MVC pattern. Note that each of these scripts performs the same set of operations but on a different database table.
I then created a second database table and copied all the scripts for the first table and amended all the references to point to the second table. As you can imagine this resulted in a great deal of duplicated code, so I had to quite a bit of refactoring to do. I started by examining each pair of scripts which contained duplicated code looking for ways to create code which could be reused.
Note that the abstract class contains a collection of common table methods as well as a collection of common table properties.
<?php require 'classes/foobar.class.inc'; $object = new foobar; $fieldarray = $object->insertRecord($_POST); if (empty($object->errors)) { $result = $object->commit(); } else { $result = $object->rollback(); } // if ?>
Note that this is an example of tight coupling as this particular Controller can only be used with a particular Model. There is no reusability.
After a bit of experimenting I discovered that I could replace the hard-coded class name with the contents of a variable, which required another script to load the value into that variable as shown below:
-- a COMPONENT script <?php $table_id = "foobar"; // identify the Model $screen = 'foobar.detail.screen.inc'; // identify the View (a file identifying the XSL stylesheet) require 'std.add1.inc'; // activate the Controller ?> -- a CONTROLLER script (std.add1.inc) <?php require "classes/$table_id.class.inc"; $object = new $table_id; $fieldarray = $object->insertRecord($_POST); if (empty($object->errors)) { $result = $object->commit(); } else { $result = $object->rollback(); } // if ?>
Note that this is an example of loose coupling as this particular Controller can be used with any available Model. There is maximum reusability.
This meant that, by taking advantage of the polymorphism which I had created with my abstract class, I could create a separate version of the component script for each user transaction, but share the same controller script. Without realising it I had actually implemented a new variation of dependency injection.
My data Dictionary was similar to the Application Model which was built into the UNIFACE IDE, but worked in reverse. With UNIFACE you described your table structure within the Application Model, then exported it to your DBMS by generating CREATE TABLE scripts. With my Data Dictionary you create (or amend) your table structure within the DBMS, then import it into the Data Dictionary before exporting it to PHP by creating a table class file and a table structure file. Note that as well as the list of field specifications the table structure file also identifies the primary key, any candidate (unique) keys, and any relationships with other tables either as a parent or a child.
While testing the code which I had written my mind switched from developer mode to user mode, and either I or my business partner began to notice areas where the usability could be improved. This is now known as the User Experience (UX). These changes were made to components within the framework and not to any application classes, but they were then globally available to every transaction in every application.
dml.mysql.class.inc file, then changed the "_dml_" methods in the abstract class to call the relevant methods in this new class. I then copied this new class to create a new version called dml.mysqli.class.inc, then added code at the start of each of the "_dml_" methods to find out which database extension should be loaded by using an entry in the configuration file (config.inc). This completed my implementation of the Data Access layer in the 3-Tier Architecture. When other database vendors released their free versions, first PostgreSQL, then Oracle, followed by SQL Server, I was able to create class files for them as well.Sometimes an enhancement to the framework requires an additional set of database tables, so this is implemented by creating a new subsystem with its own set of user transactions. Unlike an application subsystem this may also require a few changes to some framework components in order to complete the integration. Some examples are shown below:
insertRecord(), updateRecord() and deleteRecord() methods in each of the dml.???.class.inc files in order to establish what columns had been changed so it could write those changes to the AUDIT database. I also added an $audit_logging property to the abstract table class so that this audit logging could be turned ON or OFF for individual tables.Both of these options are vulnerable to attack by determined hackers, but a more secure option is now available - transferring data over a private blockchain. Similar to my Workflow subsystem this involved the creation of a new database and associated maintenance tasks, with the necessary processing built into the framework, not any application component. Just like the addition of the responsive web option this was completed in just one man-month.
The success of my toolkit was down to the decisions which I made based on my own experience and judgement. When compared with the practices followed by my contemporaries I can achieve more with less effort. When I was later informed that my work must surely be rubbish because I wasn't following an "approved" set of best practice I looked as these practices and quickly concluded that they were not fit for purpose. These are summarised below.
Here is a summary of the design decisions I made which helped put the "rapid" into my rapid application development framework:
Because I have higher volumes of reusable software than my contemporaries there are a lot of areas where I can achieve results with less effort simply because of the amount of code which I *DON'T* have to write. I reduced and simplified the amount of code I had to write by ignoring certain "best practices" and adopting a set of home-grown "better practices"
Further details on this topic can be found in Bad practices that I avoid.
I am a pragmatist, not a dogmatist like most of my critics. This means that I am results-oriented and not rules-oriented. I decide for myself which is the most cost-effective way of achieving the desired result instead of following, like a robot, the "advice" given by others. I can think for myself. I don't let others do my thinking for me. I developed my framework in PHP4 and found that its support for Encapsulation, Inheritance and Polymorphism was more than adequate. Although many new features have been added to PHP since then I do not use them simply because I cannot find a use for them. Either they do something which I don't need, or I have already satisfied that need with a less complicated solution.
Further details on the features which I don't use can be found in PHP features which I avoid.
The following articles describe aspects of my framework: