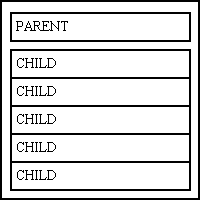
Figure 1 - A typical database application
")
The title of this article should not be news to any programmer who has been taught OO theory, and then tries to apply that theory when building a database application. The established view is that OO design is sacrosanct and that the persistence mechanism (ie. the database) is just a minor implementation detail that can be left till later. My view is completely the opposite - in any database application it is the database design which is sacrosanct, and it is the software which should be constructed to follow the database design. I do not make any attempt to hide the fact that I am talking to an SQL database, instead I embrace the fact and build my software specifically to take advantage of the power and flexibility of SQL.
The usual steps when following the established view are as follows:
Does this sound familiar? Do you still have problems trying to merge OO theory with database theory? I have been building database applications for 35+ years, and I don't have those problems. How is this? My personal approach to developing database applications with OOP can be summed up very simply:
That last point is very important as it has enabled my Table Oriented Programming approach to become so automated that it outperforms all other major frameworks. Starting with the database design I can do the following:
With my approach I can generate a family of forms for a database table in five minutes without having to write a single line of code - no PHP, no HTML, no SQL. Although the generated user transactions contain only basic functionality, it is very easy for developers to insert custom code into the generated classes in order to deal with complex business rules.
Many years ago I remember someone saying in a newsgroup posting that Object Oriented Programming (OOP) was not suitable for database applications. As "evidence" he pointed out the fact that relational databases were not object oriented, that it was not possible to store objects in a database, and that it required the intervention of an Object Relational Mapper (ORM) to deal with the differences between the software structure and the database structure. I disagreed totally with this opinion for the simple reason that I had been using OOP to build database applications for several years, and I had encountered no such problems. As far as I was concerned it was not that OOP itself was not suitable for writing database applications, it was his lack of understanding of how databases work coupled with his questionable method of implementing OO concepts in his software which was causing the problem. You have to understand how databases work before you can build software that works with a database.
How do I have the audacity to say such a thing? It has become more and more obvious to me that too many proponents of OO seem to think that there is only one way to implement the concepts of OO, and that you should bend your software to adhere to these concepts rather than bending the concepts to allow for a more elegant or efficient solution to deal with the problem at hand. These people love to document their ideas as a series of guidelines, rules or principles, and they love to teach these rules to the next generation of software developers who then believe that these rules are the gospel truth, are cast in stone and cannot be questioned. Anyone who dares to question their beliefs, who dares to stray from the path of orthodoxy is liable to be branded as a heretic, an outcast, a pariah. Well I am a heretic, and proud of it.
Anyone who has been taught that there is only one way to "do" OOP has been seriously misinformed, and anyone who is unwilling to even contemplate that there may actually be more than one way will be doomed forever to be constrained by the limitations of closed minds and inferior intellects. These things called "guidelines", "rules", "principles", "standards" or "best practices" are supposed to be a safety net to help the unwary from making silly mistakes, but when applied too rigidly this "safety net" can become a millstone around the necks of those who have enquiring minds and who wish to explore new possibilities. The only way that progress can be made is to try something different, something new, which means ditching the current dogma and thinking outside of the box. In his article The Art of War applied to software development the author Jose F. Maldonado states the following:
If you're a talented developer, you need to think outside the box. The box is there to prevent incompetent people from wrecking stuff. It's not for you.
One common complaint I hear from developers who move from a non-OO to an OO language is that OO programs seem to be slow and cumbersome when compared with what they are used to. I think that the reason for this is that today's programmers are taught to blindly follow a bunch of principles instead of being taught to design and build cost effect solutions to genuine problems. This became obvious to me when I tried to debug someone else's code which used one of the popular front-end frameworks. I stepped through every line with my debugger looking for the cause of the error, but all I found was total confusion. All I had done was run through a single index page, but I had to step through 100 classes which had so many levels of indirection I did not have a clue as to which class did what. Anybody who thinks that using 100 classes to paint a simple index page is in serious need of a reality check. I was so disgusted with this framework that I immediately purged it from my system and refused to have anything more to do with it. My decades of prior experience told me that this was NOT the way that software should be written, which is why I rail against those modern practices and principles which promote the writing of bad software.
My critics, of whom there are many, constantly berate me for breaking their precious rules and daring to be different, but I don't care. If I were to do everything the same as them then I would be no better than them, and I'm afraid that their best is simply not good enough. They seem to think that by following their precious rules that my software will automatically be as good as it could be, but I maintain that by breaking their silly rules that my software is actually better than theirs.
A software engineer, who may also be known as a "computer programmer", "software developer" or just plain "developer", is a person who writes computer programs for a living. I am discounting those who write software simply as an academic exercise or a hobby as they are not professionals, and their opinions don't count. This leads me to the following definition:
The purpose of a software developer is to develop cost-effective software for the benefit of the paying customer, NOT to impress other developers with the cleverness of their code.
To answer the question "What does a programmer do?" I offer the following explanation:
Computer programming involves writing instruction manuals for idiots.
- Why an "instruction manual"? You cannot get a computer to follow a procedure that cannot first be explained to a human being. You must start with a set of human-readable instructions and convert them into computer-readable instructions.
- Why an "idiot"? A computer may be fast, but it is still an idiot in the sense that it can do nothing but obey instructions, and it will follow whatever instructions it has been given to the letter. If those instructions don't go down to the lowest possible level of detail, are not precise, exact and unambiguous, then the computer may not do what you expect and therefore may not produce the results you expect.
Here is another way of saying the same thing:
The job of a computer programmer is to take an instruction manual which a human being can understand and translate it into instructions which a computer can understand. While it is possible for a human being to take instructions which are imprecise and make educated guesses, this is beyond the capabilities of a computer because it is a complete idiot. If there is a hole in the logic which it is following it will fall down that hole and never emerge.
Writing software is just like writing a book, it is a work of authorship, and some people are good at it while others are not. Writing a book of recipes for other people to follow requires a greater level of skill than following a recipe written by someone else. It is also possible for some people to think that they have followed a recipe to the letter only to discover that the resulting product is no better than a dog's dinner. Some programmers seek to prove how clever they by writing clever code, but sometimes they go too far end end up by being too clever by half and producing code that is so complex that it is difficult for other programmers to understand and therefore maintain. Various people have expressed their opinions of this topic over the years:
Everything should be made as simple as possible, but not simpler.
Any intelligent fool can make things bigger, more complex, and more violent. It takes a touch of genius - and a lot of courage - to move in the opposite direction.Albert Einstein
All that is complex is not useful. All that is useful is simple.Mikhail Kalashnikov
Programs must be written for people to read, and only incidentally for machines to execute.Abelson and Sussman, Structure and Interpretation of Computer Programs, published in 1983
Any fool can write code that a computer can understand. Good programmers write code that humans can understand.Martin Fowler, author of Patterns of Enterprise Application Architecture (PoEAA)
Any idiot can write code than only a genius can understand. A true genius can write code that any idiot can understand.
The mark of genius is to achieve complex things in a simple manner, not to achieve simple things in a complex manner.Tony Marston (who???)
This is the basis of the KISS Principle which has been a solid engineering principle for many decades. If you ignore this principle then you may end up with something which looks more like one of those eccentric machines designed by Heath Robinson or Rube Goldberg.
I am a pragmatist, not a dogmatist, which means that I am results oriented instead of rules oriented. A dogmatist will follow a set of rules without question and automatically assume that the results, however bad, must be acceptable. A pragmatist will not constrain himself by artificial rules but will instead do whatever is necessary, which may include breaking existing rules and making new ones, in order to produce something which is cheaper, quicker or better. If I can write simple code to achieve a complex task then why should I rewrite it to achieve the same thing in a more complex manner just so that it conforms to your idea of how software should be written?
Writing software that pleases the paying customers should always take priority over writing software that pleases other developers. If I can write software in half the time that you can, at half the cost, and with more features, then whose software is more likely to come out on top in the market place? Customers do not care about code purity, they only care about bang for their buck.
When I am either designing an application or writing code for components of that application there are only three limitations that I am prepared to accept:
That last item includes my personal experiences which have accumulated over many years while working with numerous teams on numerous projects. If I have encountered an idea in the past that turned out to be bad then no amount of argument will persuade me to try that bad idea again. If I have encountered an idea in the past that turned out to be good I will continue to use that idea unless someone comes up with a better alternative. Simply saying that a new idea is "better" is not good enough. When some so-called "expert" writes an article saying "Don't do it like that, do it like this" I will not jump on the bandwagon until I see absolute proof that the idea is actually better, and only then will I weigh up the costs of changing my code to see if the benefits outweigh the costs. While I am prepared to spend 1p to save £1, I am not prepared to spend £1 to save 1p.
Today there is computer software in an amazing number of devices which is used for an amazing number of purposes, such as:
I have never done any of that. I have only ever worked on business systems, such as those written to run on the LEO machine which was, in 1951, the first computer used for commercial business applications. It started with software to perform bakery valuations, but went on to deal with payroll, inventory, orders, production schedules, delivery schedules, invoicing, costing and management reports. This type of software is characterised by the fact that it is not controlled by, nor does it exert control over, any external devices or objects. It simply deals with data which records events that are deemed to be important to the business. Such systems have three distinct parts:
This simple structure is shown in Figure 1:
Figure 1 - A typical database application
Note that the data does not go directly from the input device to the database - it goes through some intermediate software which may process the data in some way before it writes the data to as many tables and columns in the database as necessary. When data is retrieved from the database it may come from several columns in several tables before it is assembled and made ready for display on the output device.
Because such systems are designed to do nothing but process data they are known as Data Processing Systems, although the term Data Processing (DP) has subsequently been updated to Information Technology (IT).
In the case of the LEO system each of its stores would, at the end of each working day, submit their sales figures showing what quantities of which products had been sold. The software would then accumulate the sales figures from each store to show the total figures for all stores. This information would then enable the company to identify how much of each product needed to be produced overnight, and then how much of each product needed to be despatched to which store in the morning.
In those early days the data was input either on punched card or paper tape, and the output was on printed reports. There were no online processes as everything was done in batches. The current figures were not available in real-time as the printed report could only show the state of play as at the end of the previous working day after that day's data had been input and processed. It is a totally different story today. Input via paper tape and punched card has been replaced by input via a Graphical User Interface (GUI) on a monitor using a keyboard and a mouse. In some cases the manual input of data can be automated if the device which records particular events can send its event data directly to the system as and when each event happens. When you go through the checkout in a supermarket, for example, you will be given a receipt which shows the identity, quantity and price of every item you purchased. This data can also be sent directly to the store's central computer, thus avoiding the tedious task of having someone go through all the printed copies of the day's receipts and manually inputting that data. As the central database is being updated in real-time as each event takes place, it also follows that online summaries of that data can also be made available in real-time, making the figures a few minutes old instead of a day old.
The use of computer monitors made it easy to replace paper forms or documents with an electronic representation of the same forms into which the user could type data instead of writing it on a piece of paper. Before the internet all forms were compiled and therefore specific to whatever programming language was being used.
With the rise of the internet we now have E-commerce where customers use their own personal computers to visit an organisation's website and purchase products without having to visit a physical store. This is done through a web browser which runs on the client (customer's) device, which means that the user interface now consists of nothing but HTML forms which are totally independent of whatever programming language is being used on the organisation's server.
I now build database applications for the enterprise in the PHP language, which means that they are web applications and can be accessed from any web-enabled device. Note that these are web applications and are totally different from web sites. My main application, an ERP package, has 300+ database tables, 500+ relationships and 2,500+ user transactions.
When analysing the data requirements for a system the database designer must go through a process known as Data Normalisation in order to design a database structure - a series of tables with columns and relationships - which holds all the data required so that it can be both written and retrieved as efficiently as possible. This can be summed up as "A place for everything, and everything in it's place". The design of the database is very important - get it wrong and this will have a detrimental effect on the performance of the entire system. Note that it is not possible to write clever code to circumvent the effects of a bad database design.
If you ask 10 different programmers the question "What is OOP?" you will get 10 different answers, and they will probably all be wrong. The truth is a lot simpler than that, but this appears to be too simple for the let's-make-it-more-complicated-than-it-really-is-just-to-prove-how-clever-we-are brigade, so they have invented a whole bunch of optional extras and useless principles. When I came to learn OOP in late 2001 and early 2002 the resources which were available on the internet were very small in number and far less complicated. All I had to go on was a description of what made a language object oriented in Object Oriented Programming from October 2001 which stated something similar to the following:
Object Oriented Programming is programming which is oriented around objects, thus taking advantage of Encapsulation, Inheritance and Polymorphism to increase code reuse and decrease code maintenance.
To do OO programming you need an OO language, and a language can only be said to be object oriented if it supports encapsulation (classes and objects), inheritance and polymorphism. It may support other features, but encapsulation, inheritance and polymorphism are the bare minimum. That is not just my personal opinion, it is also the opinion of the man who invented the term. In addition, Bjarne Stroustrup (who designed and implemented the C++ programming language), provides this broad definition of the term "Object Oriented" in section 3 of his paper called Why C++ is not just an Object Oriented Programming Language:
A language or technique is object-oriented if and only if it directly supports:
- Abstraction - providing some form of classes and objects.
- Inheritance - providing the ability to build new abstractions out of existing ones.
- Runtime polymorphism - providing some form of runtime binding.
| Encapsulation | The act of placing data and the operations that perform on that data in the same class. The class then becomes the 'capsule' or container for the data and operations. This binds together the data and functions that manipulate the data.
More details can be found in OOP for heretics |
| Inheritance | The reuse of base classes (superclasses) to form derived classes (subclasses). Methods and properties defined in the superclass are automatically shared by any subclass.
More details can be found in OOP for heretics |
| Polymorphism | Same interface, different implementation. The ability to substitute one class for another. By the word "interface" I do not mean object interface but method signature. This means that different classes may contain the same method signatures, but the result which is returned by each method will be different as the code behind each method (the implementation) is different in each class.
More details can be found in OOP for heretics |
Object Oriented programming is supposed to be totally different from Procedural programming, but how different is it in reality? According to the definitions above it could be achieved by taking a procedural language and adding in the ability to support encapsulation, inheritance and polymorphism. This was done when PHP 3 was upgraded to PHP 4. If you take code from a procedural function and put it in a class method you will see that the two pieces of code are exactly the same, and when executed they will produce exactly the same result. The only difference is in how they are called.
However, simply by taking all your current procedural functions and putting them into a single class will not result in either efficient or maintainable software. The idea of Object Oriented programming is that you break an entire application down into a collection of modules, classes or objects which can work together in unison, but using inheritance and polymorphism to incorporate more reusable code and less duplicated code. It would not be a good idea to put the entire application into a single module (known as a God Object), nor would it be a good idea to have as many modules as there are grains of sand in the desert (known as Anemic Domain Model) as neither of these two extremes would result in code which would be easy to read, easy to understand, or easy to maintain. Between these two extremes lies the middle ground, but describing to novice programmers how to get to this middle ground is not an easy task. You have to know when a module is too big and should be broken down into smaller units, but you also have to know when to stop this "breaking down" process otherwise you will end up with a system which is too fragmented. Simply dividing an application into lots of little classes will not guarantee that the application will perform well and be readable, understandable and maintainable. Care has to be taken in the design of each module, and the way in which control is passed from one module to another, so that you avoid the generation of spaghetti code, ravioli code or lasagna code. One way to judge the quality of software is to look for high cohesion and low coupling, as explained below:
| Abstraction | The process of separating the abstract from the concrete, the general from the specific, by examining a group of objects looking for both similarities and differences. The similarities can be shared by all members of that group while the differences are unique to individual members.
More details can be found in The meaning of "abstraction" |
| Cohesion | Describes the contents of a module. The degree to which the responsibilities of a single module/component form a meaningful unit. The degree of interaction within a module. Higher cohesion is better. Modules with high cohesion are preferable because high cohesion is associated with desirable traits such as robustness, reliability, reusability, extendability, and understandability whereas low cohesion is associated with undesirable traits such as being difficult to maintain, difficult to test, difficult to reuse, difficult to extend, and even difficult to understand.
In his book Structured Analysis and System Specification Tom DeMarco describes cohesion as: Cohesion is a measure of the strength of association of the elements inside a module. A highly cohesive module is a collection of statements and data items that should be treated as a whole because they are so closely related. Any attempt to divide them would only result in increased coupling and decreased readability. In his blog Glenn Vanderburg has this description of cohesion: Cohesion comes from the same root word that "adhesion" comes from. It's a word about sticking. When something adheres to something else (when it's adhesive, in other words) it's a one-sided, external thing: something (like glue) is sticking one thing to another. Things that are cohesive, on the other hand, naturally stick to each other because they are of like kind, or because they fit so well together. Duct tape adheres to things because it's sticky, not because it necessarily has anything in common with them. But two lumps of clay will cohere when you put them together, and matched, well-machined parts sometimes seem to cohere because the fit is so precise. Adhesion is one thing sticking to another; cohesion is a mutual relationship, with two things sticking together. In his blog Derek Greer has this description: Cohesion is defined as the functional relatedness of the elements of a module. If all the methods on a given object pertain to a related set of operations, the object can be said to have high-cohesion. If an object has a bunch of miscellaneous methods which deal with unrelated concerns, it could be said to have low-cohesion. In his blog John Sonmez describes it as follows: We would say that something is highly cohesive if it has a clear boundary and all of it is contained in one place. High cohesion can be said to have two faces:
Cohesion is usually contrasted with coupling. High cohesion often correlates with low coupling, and vice versa. |
| Low Cohesion |
Low cohesion implies that a given module performs tasks which are not very related to each other and hence can create problems as the module becomes large. Low cohesion in a module is associated with undesirable traits such as being difficult to maintain, test, reuse, and even understand. Low cohesion often correlates with tight coupling.
An example of low cohesion can be found at 1-Tier Architecture. |
| High Cohesion |
High cohesion is often a sign of a well-structured computer system and a good design, and when combined with loose coupling, supports the general goals of robustness, reliability, reusability, and understandability. Cohesion is increased if:
Advantages of high cohesion are:
While in principle a module can have perfect cohesion by only consisting of a single, atomic element - having a single function, for example - in practice complex tasks are not expressible by a single, simple element. Thus a single-element module has an element that is either too complicated in order to accomplish a task, or is too narrow, and thus tightly coupled to other modules. Thus cohesion is balanced with both unit complexity and coupling. An example of high cohesion can be found at 3-Tier Architecture. |
| Coupling | Describes how modules interact. The degree of mutual interdependence between modules/components. The degree of interaction between two modules. Lower coupling is better. Low coupling tends to create more reusable methods. It is not possible to write completely decoupled methods, otherwise the program will not work! Tightly coupled systems tend to exhibit the following developmental characteristics, which are often seen as disadvantages:
Note that this is restricted to when one module calls another, not when one class inherits from another. Coupling is usually contrasted with cohesion. Low coupling often correlates with high cohesion, and vice versa. This term is often interchangeable with dependency. Note that some people like to say that inheritance automatically produces tight coupling between the superclass and the subclass, but this only causes a problem when you extend one concrete class into a different concrete class. As I only ever create a concrete table class from my abstract table class this problem does not arise. Good object-oriented design requires a balance between coupling and inheritance, so when measuring software quality you should focus on non-inheritance coupling. |
| Loose Coupling |
Loosely coupled systems tend to exhibit the following developmental characteristics, which are often seen as advantages:
In this wikipedia article there is a description of loose coupling: Message coupling (low) In the same article it also states Low coupling refers to a relationship in which one module interacts with another module through a simple and stable interface and does not need to be concerned with the other module's internal implementation. |
| Tight Coupling |
Tightly coupled systems tend to exhibit the following developmental characteristics, which are often seen as disadvantages:
In this wikipedia article there is a description of tight coupling: Content coupling (high) |
| Dependency | Dependency, or coupling, is a state in which one object uses a function of another object. It is the degree that one component relies on another to perform its responsibilities. It is the manner and degree of interdependence between software modules; a measure of how closely connected two routines or modules are; the strength of the relationships between modules.
Coupling is usually contrasted with cohesion. Low coupling often correlates with high cohesion, and vice versa. Low coupling is often a sign of a well-structured computer system and a good design, and when combined with high cohesion, supports the general goals of high readability and maintainability. High dependency limits code reuse and makes moving components to new projects difficult. Lower dependency is better. You can only say that "module A is dependent on module B" when there is a subroutine call from A to B. In this situation it would be wrong to say that "module B is dependent on module A" because there is no call from B to A. If module B calls module C then B is dependent on C, but it would be wrong to say that A is dependent on C as A does not call C. Module A does not even know that module C exists. Tight coupling arises when Module A can only call Module B, and Module B can only be called by Module A. In this situation there is no scope for reusability. It also arises when a change to one of the modules requires corresponding changes to be made to the other module. Loose coupling arises when moduleA can be used with any module from Group B, or even better when any module from group A can be used with any module from group B. In this situation the scope for reusability is unlimited. In my framework, for example, any Controller can be used with any Model. It also arises when a change to one of the modules does not require corresponding changes to be made to the other module. In my framework, for example, I can alter the columns in a database table without having to change either the Model or the Controller. The idea that loosely coupled code can be further "improved" by making it completely de-coupled (via Dependency Injection) shows a complete misunderstanding of what the terms dependency and coupling actually mean. If moduleA calls moduleB then there *IS* a dependency between them and they *ARE* coupled. All that Dependency Injection does is move the place where the dependent object is instantiated, it does *NOT* remove the fact that there *IS* a dependency and coupling between them. |
I don't use any of the later optional extras for the simple reason that I can achieve what I want to achieve without them. As far as I am concerned any programmer who is incapable of writing cost-effective software using nothing more than encapsulation, inheritance and polymorphism is just that - incapable.
Today's programmers are taught that before they can write a single line of code they must go through a process known as Object Oriented Design (OOD) or Object Oriented Analysis and Design (OOAD) which involves the production of the following:
Students are also taught to follow such principles as GRASP and SOLID. There are others, such as the following which can be found in The Principles of OOD:
I ignore all of these principles for the simple reason that all they say is "Do it this way!" without explaining why. What problems are these principles meant to solve? If I don't follow these principles what bad thing happen? Reasons such as "to follow best practices" or "to be consistent" or "to be up-to-date" just do not work for me.
My programming career started in 1976 on a UNIVAC mainframe where I used some Assembler but mostly COBOL. I later worked on a Data General Eclipse writing business applications using COBOL and the INFOS database (a hierarchical database) and which used character mode terminals. I then moved on to a Hewlett-Packard 3000 to write business applications using COBOL and the IMAGE/TurboIMAGE database (a network database) using block mode terminals. These terminals were all monochrome monitors which had a keyboard but no mouse. When personal computers became available my company switched to the UNIFACE language and used a variety of relational databases.
COBOL was a procedural language in which the source code of each program had two distinct parts - a Data Division for all data structures, and a Procedure Division for all code. The two were entirely separate, and it was not possible to mix data and code in the same division. This was a strictly-typed language as you had to define a data item, with its type, in the Data Division before you could reference that data item with code in the Procedure Division. The code would not compile if you tried to insert data of the wrong type into a variable, such as putting a string into a number, or by accessing a variable in the wrong way such as trying to execute an arithmetical function on a string.
UNIFACE was a Component-based and Model-driven language which was based on the Three Schema Architecture with the following parts:
While all COBOL code was lumped together into single units in what was known as the Single Tier Architecture, the fact that UNIFACE had a separate driver for each DBMS turned it into the 2-Tier Architecture. When Uniface 7.2.04 was released it allowed all business rules and database access to be moved out of the Form components into separate Service components, thus providing the 3-Tier Architecture. Communication between the Form components in the Presentation Layer and the service components in the Business Layer was via XML streams, so this caused me to become familiar with XML. Although UNIFACE could also perform XSL Transformations, it could only transform an XML document into another XML document. It could not transform XML into HTML which I thought was a serious mistake as its method of generating HTML was far too clunky and cumbersome. This version also introduced the concept of Component Templates which I later used as the basis for my Transaction Patterns.
The majority of my programming work was done while working for software houses, which meant that after designing and building a project for one client I would then move on to another project for another client. To speed up development I created a development framework in COBOL in 1986, which was adopted as the company standard. I later converted this to a development framework in UNIFACE.
All the above were compiled languages which produced applications which ran on the desktop. My first attempt at a web application was a complete disaster for two main reasons:
In my 25+ years of designing databases and the applications which used them I learned a host of valuable lessons, including the following:
After learning how HTML pages could be built I decided that UNIFACE was the wrong language for web applications, so I decided to switch to a more appropriate language. I had a brief look at Java, but it looked too much like Fortran to me, so I gave it the elbow. I chose PHP because it was purpose built for the web, I liked the way it looked, I liked that it was dynamically typed, I liked that I could download and install all the relevant open source software onto my PC for free, and I liked that there was oodles of free online documentation and tutorials. After quickly learning how to write scripts which combined SQL with HTML I then learned how easy it was to take SQL output and insert it into an XML document, then transform that document into HTML using XSL stylesheets.
Having built development frameworks in both of my previous languages I set about creating a new framework in PHP. Right from the start I wanted this framework to include the following:
The first thing I noticed about putting code into a class is that to make it work you actually need two components:
Following on from my experience with UNIFACE I decided to put all classes for point #1 in the Business layer, and put all the components for point #2 in the Presentation layer. Why? Because it is the Presentation layer which calls the Business layer, so it is the Presentation layer which instantiates the Business layer component into an object, then calls methods on that object.
As PHP was the first language I used with OO capabilities I wanted to find out if I could use those capabilities in my new framework. Having read that OOP consisted of nothing more than Encapsulation, Inheritance and Polymorphism I decided that all the components in my Business layer would be constructed from classes, one for each database table. This followed on from my UNIFACE experience where each component in the Business layer was built around an entity in the Application Model, and each entity and its fields mapped directly to a database table and its columns. This decision - one class for each database table - seemed like a no-brainer to me, so imagine my surprise when I was informed some time later that "proper" OO programmers don't do it that way! I laughed so much the tears ran down my trouser leg! If you look at some of their arguments in Having a separate class for each database table is not good OO you should see the reason for my mirth.
I started my new framework by taking my database schema and building it in MySQL, then by building the transactions to maintain the contents of one of those tables. Programmers who have worked on database applications for any length of time should know that the most common set of transactions is a Forms Family which is shown in Figure 2:
Figure 2 - A typical Family of Forms
")
Here is a brief description of each of these components:
Note the following:
Figure 3 - Sharing XSL files
")
By having XSL stylesheets which can be shared I am reducing code duplication and increasing maintainability.
I started by writing three simple scripts:
After looking at the code for several sample applications which could be downloaded from the web I made one important decision that I have never regretted, even though I have been told many times that it is wrong - I decided that instead of having a separate variable for each column in a database table I would have a single $fieldarray variable which would hold the data for any number of columns and any number of rows. This is how SQL works after all, it deals with sets of data and not one column at a time. This meant that I could insert the whole of the HTTP POST array into my table class as a single variable and not have to unpick it into separate columns. This also meant that I could very easily vary the contents of the $fieldarray at will without having to modify any setters or getters. It also simplified the creation of XML documents as my code could simply step through the array using the foreach function in order to identity each column name and its value.
I then copied the class for the first table to another class which I then amended to deal with a different database table. This meant that I now had two huge table classes which contained a great deal of duplicated code which is not a good idea in any application. The documented technique in OO to deal with duplicated code between classes is inheritance, so my next step was to create a superclass to contain all the common code so that each table subclass could inherit and thereby share this common code.
Starting with my two huge table classes I created an abstract table class (a superclass) to contain the shared code, modified the two concrete table classes to inherit from this abstract class, thus making them into subclasses, then gradually moved code out of each concrete class into the abstract class. This exercise produced the following:
The scripts which I used to call methods on the table class was the next to be refactored as each contained the same code with the only difference being the name of the class which had to be instantiated into an object. Because PHP is just a simple and flexible language I found it very easy to replace this code:
require "classes/foobar.class.inc"; $dbobject = new foobar;with this:
require "classes/$table_id.class.inc"; $dbobject = new $table_id;
where $table_id is passed down by a separate smaller script. I now have one of the small Component scripts for each user transaction while the larger script which does all the work is known as a Controller script, with a separate script for each of my Transaction Patterns. Those of you who are still awake should recognise this as a form of Dependency Injection.
Because my Presentation Layer consisted of two separate components it was pointed out that what I had actually done was create an implementation of the Model-View-Controller design pattern. I checked the definition and could see that this was, in fact, quite true. If you look at the description of my three simple scripts you should see that #1 is the Model, #2 is the Controller and #3 is the View.
The official definition of polymorphism is Same interface, different implementation
. This means that several different objects contain an identical method signature, so calling that same method on those different objects will run different implementations (code) and produce different results. The possibility for polymorphism in my framework is greatly increased by virtue of the fact that when a Controller calls a method on a Model that method was defined in the abstract class and inherited by the concrete table class (Model), so the same methods are effectively duplicated in each Model class. So if I have the following code in a Controller:
require "classes/$table_id.class.inc"; $dbobject = new $table_id; $fieldarray = $dbobject->insertRecord($_POST);
you should see that simply by changing the value of $table_id the same method is being called on a different object. The implementation is different by virtue of the fact that the contents of the $_POST array will be validated against the structure of the specified table, and the SQL query which is generated will be specific to that particular table. My single View object can also be used with any Model as it does not contain any hard-coded references to either table names or column names. The Controller calls the Model, and when the Model has finished the Controller injects that Model object into the View, and all the View has to to is call $fieldarray = $object->getFieldArray(); and it has access to all the application data from that object. By using the foreach function on this array it can obtain the name and value for every data item and insert it into the XML document.
This simple decision - by using a single array variable for all object data instead of a separate variable for each individual column - made it possible for me to construct Controllers and Views which do not contain any hard-coded references to any table names or column names. This means that those components can be used on any Model as the methods that they use can work on any Model. This is how to make use of polymorphism. This is how I can produce 2,000 user transactions from 12 XSL stylesheets, 40 Controllers and 300 Models. Does your framework have that level of reusability? If not then why is your framework "correct" and mine "incorrect"?
This arrangement was not pure 3-Tier as the code which generated the SQL queries was embedded in the Model (Business layer), so I separated it out and put it into a separate class which, as it exists in the Data Access layer, is known as the Data Access Object (DAO). This was particularly useful when the original mysql_ extension was superseded by the improved mysqli_ extension for accessing MySQL version 4.1 and above. I later added classes to work with other databases, such as PostgreSQL, Oracle and SQL Server. There are some programmers who think that the ability to change databases in an application is rarely needed as, once implemented, it is very rare for an organisation to switch from one DBMS to another, but they are missing one vital point - I do not work on an in-house application for a single organisation, I am a contractor who provides software which can be used by any number of organisations using a DBMS of their choice. They may never switch to another DBMS once the software has been deployed, but they do appreciate having a choice to begin with.
High Cohesion can be achieved if:
Developers often turn to the Single Responsibility Principle (SRP) or Separation of Concerns (SoC) to help them identify how to split their application into cohesive modules. These two principles, which use different words for the same concept, state the following:
Every module or class should have responsibility over a single part of the functionality provided by the software, and that responsibility should be entirely encapsulated by the class. All its services should be narrowly aligned with that responsibility.
That description is still a bit vague and open to massive amounts of interpretation and mis-interpretation, so in his articles SRP: The Single Responsibility Principle, The Single Responsibility Principle and Test Induced Design Damage? the author Robert C. Martin says the following:
GUIs change at a very different rate, and for very different reasons, than business rules. Database schemas change for very different reasons, and at very different rates than business rules. Keeping these concerns separate is good design.
This is the reason we do not put SQL in JSPs. This is the reason we do not generate HTML in the modules that compute results. This is the reason that business rules should not know the database schema. This is the reason we separate concerns.
When I read those statements I can clearly see that he is describing the separation of GUI logic, business logic and database access logic which corresponds EXACTLY with the definition of the 3-Tier Architecture which is precisely what I have implemented. As my software also exhibits the characteristics of having high cohesion I do not think that I can say anything other than "Job Done!"
Loose Coupling can be achieved if:
Coupling occurs whenever one module calls another, such as when a Controller calls a Model. Here is an example of tight coupling:
<?php $dbobject = new Person(); $dbobject->setUserID ( $_POST['userID'] ); $dbobject->setEmail ( $_POST['email'] ); $dbobject->setFirstname ( $_POST['firstname']); $dbobject->setLastname ( $_POST['lastname'] ); $dbobject->setAddress1 ( $_POST['address1'] ); $dbobject->setAddress2 ( $_POST['address2'] ); $dbobject->setCity ( $_POST['city'] ); $dbobject->setProvince ( $_POST['province'] ); $dbobject->setCountry ( $_POST['country'] ); if ($dbobject->updatePerson($db) !== true) { // do error handling } ?>
An alternative to this would be to pass each column as a separate argument on the method call like the following:
$result = $dbobject->update($_POST['userID'], $_POST['email'], $_POST['firstname'], $_POST['lastname'], $_POST['address1'], $_POST['address2'], $_POST['city'], $_POST['province'], $_POST['country'], );
These are both examples of tight coupling because of the following:
Here is an example of loose coupling:
<?php require_once 'classes/$table_id.class.inc'; // $table_id is provided by the previous script $dbobject = new $table_id; $result = $dbobject->updateRecord($_POST); if ($dbobject->errors) { ... error handling } // if ?>
This clearly has the following advantages:
$table_id.In my first attempt at having a separate class for each database table I included an array called $fieldlist which was a simple list of field names that were contained within that particular table. This meant that when building the SQL query I could ignore entries in the $_POST array which did not belong in that table, such as the SUBMIT button. Then when it came to validating user input I quickly got tired of writing the same code for different columns on different tables, so I sought a much easier method. It was obvious to me that each column had a data type (number, string, date, boolean, et cetera) and that the validation code simply checked that a particular value fell into the bounds of the data type specified for that column. This caused me to convert the $fieldlist array in the $fieldspec array which contained a list of field names as well as their specifications (type, size, et cetera). It then became easy to write a validation class which took the array of field values and the array of field specifications and checked that each field value matched its particular specifications. I then changed the abstract table class so that this validation object was called automatically and did not require any extra coding by the developer.
If the validation object detects an error all it does is put an entry in the object's $errors array just like in the following code sample:
$this->errors['fieldname'] = "This value should be a number";
This array is then extracted by the View object so that it can associate each error message with the relevant field when writing to the XML document. The XSL stylesheet will then display each error message underneath the offending value in the HTML output.
I have been using this simple mechanism for over a decade now, so why are there still novices out there writing articles like How to validate data which call for large volumes of code in order to obey sets of artificial rules? Those rules don't exist in my universe, so I don't have to obey them, and my code is all the better because of it.
It is one thing to provide code libraries which carry out all the basic and standard processing, but there will always be the need in some user transactions to do something which is a little more complicated or a little more specialised. I solved this need by populating my abstract table class with some customisable methods which are called automatically in certain places of the current processing cycle, but which are empty. These "customisable" methods can easily be recognised as they have a "_cm_" prefix. If the developer wishes to add custom code all he has to do is identify the correct method, copy it from the abstract table class to his concrete class, then insert the necessary code. The method that now exists in the concrete table class will now override the empty method in the abstract table class.
If you look as this collection of UML diagrams you will see what customisable methods are available for each of the major operations and when they are called.
When I created my first LIST and DETAIL stylesheets you should notice that they contained hard-coded references to table names and column names. This in effect meant that I had to manually create a separate set of stylesheets for each table. What a bummer! After a bit of experimentation I came up with a method which meant that instead of hard-coding the table and column names in the XSL stylesheet I could actually put those names into the XML document in a separate structure element. In order to define the contents of this element I introduced the use of a separate screen structure file, and modified my View component to read this file and write the data to the XML document. All my other XSL optimisations are documented in Reusable XSL Stylesheets and Templates. This means that I now have a small number of XSL stylesheets which can be used with any database table. I actually have 12 stylesheets which are used with 300 database tables to produce 2,000 different user transactions. How is that for reusability!
In my original implementation the $fieldspec array was hard-coded into the relevant table class. This meant that it took some effort to create the class file in the first place, and additional effort should the structure of the database table be subsequently amended. One of the labour-saving devices I had used in my COBOL days was to write a program which read the database schema and produced a text file which could be added to the project's COPY LIBRARY. This meant that every program in the system could use the central COPYLIB definition to obtain a table's structure without the programmer having to code that structure by hand and possibly introducing errors. If a table's structure ever changed it was a simple process to rebuild the COPY LIBRARY then recompile all programs without the need to change any source code. As well as reducing effort it also reduced the possibility for errors caused by incompatibilities between the program's perceived data structure and the actual database structure.
The UNIFACE language used an internal Application Model from which the CREATE TABLE scripts could be generated in order to keep the physical database synchronised with the Application Model. This mechanism had several disadvantages:
I did not want to implement the Uniface design, nor did I wish to do what others had done which was to interrogate the table's INFORMATION_SCHEMA data each time the class was instantiated as I felt that this would be too slow. I decided instead to build my own Application Model in the form of a Data Dictionary which had the following characteristics:
Although this Data Dictionary took some effort to build it has paid for itself many times over as it is now very easy to deal with both new tables and changed tables. It also does not have the disadvantages with the Unface approach:
Another advantage to my approach is that once the data is inside the Data Dictionary I can add specifications which are not available in the INFORMATION_SCHEMA such as "change text to upper or lower case", "zero fill", "blank when zero", or even to specify which HTML control is to be used in the output. When maintaining the parent and child relationships I can even specify that when a SELECT statement is being generated the framework should automatically include a JOIN to a foreign table in order to include fields from that foreign table in its output. As part of my Internationalisation feature it is also possible for the framework to automatically adjust the SQL SELECT query to retrieve translated text from the relevant database table without the need for programmer intervention. The contents of the structure file is also database independent. This means that I can generate the scripts from a MySQL database and use the same scripts against an Oracle or SQL Server database.
Once I had built the Data Dictionary and used it to create all the class files for the Model components in the Business layer and then created my library of Transaction Patterns, I then realised that it would be a simple step to add in the ability to generate user transactions (tasks) from this information. This process has the following steps:
This procedure will generate the following:
Some of these transaction patterns are the parent in a family of forms, so this procedure will also generate the child members of the family and add them to the navigation bar of the parent form.
This feature now means that starting with nothing more than the schema for an application database it is possible to import that database schema into the Radicore framework then generate all the components necessary to maintain each of those database tables without writing a single line of code. These generated components may be basic in their construction, but they are fully functional. They may be modified afterwards for cosmetic reasons, or to add in additional business rules. Once generated these files cannot be regenerated, so any modifications cannot be accidentally overwritten.
It is also important to note that the amount of code which is generated is very small, and not the huge volumes produced by other frameworks. This is because all the code for standard and basic behaviour exists as reusable modules within the framework, and these small scripts merely act as pointers to which of those modules should be used and in what order.
I learned to design and build database applications - which included designing the database as well as writing the code to access that database - decades before I used a language with OO capabilities. During that time I learned that software solutions in general should be designed to reflect the problem which is being solved, so for database applications this meant writing code which acted as the intermediary between the User Interface (UI) and the database as shown in Figure 1. I also learned that the database should be designed first using a methodology known as Data Normalisation, and, thanks to Jackson Structured Programming (JSP), that the software should be designed around the database structure. My experiences both before and after JSP convinced me of the efficacy of this statement, so I absolutely WILL NOT go back to a methodology which puts the software design ahead of the database design.
When I chose to move from writing desktop applications to web applications in 2002 I picked PHP as my new language. Even though this was PHP version 4 it had object oriented capabilities as it supported Encapsulation, Inheritance and Polymorphism, so I decided to use these capabilities to see if I could achieve the objective of OOP which was stated as follows:
Object Oriented Programming is programming which is oriented around objects, thus taking advantage of Encapsulation, Polymorphism, and Inheritance to increase code reuse and decrease code maintenance.
There are some people who say that PHP is not a "proper" OO language, but according to the man who invented the term they are wrong. These people insist that "proper" OO requires more than that, and although new OO features have been added to PHP version 5 I consider them to be nothing more than optional extras and choose to ignore them. They would not add value to my code, so I do not have any use for them. If I have written code that works then I prefer to follow the engineering principle which states If it ain't broke, don't fix it. Thus I will not tinker with working code just to make it work differently, but I would be prepared to refactor it to make it work better.
When I came to rebuild my development framework in PHP I started with the database design which I had used in previous versions of that framework. I then wrote the code in such a way as to make use of the OO features in PHP:
The levels of reusability that I have in my framework is quite remarkable. I have used this framework to build a large enterprise application which has over 450 database tables, over 1,200 relationships, over 4,000 user transactions which uses the following components:
Each new version of my framework has enabled me to be more productive than I was with the previous version - What I could achieve in a week with my COBOL framework I could achieve in a day with my UNIFACE framework, but with my new PHP framework it only takes me 5 minutes. I have also achieved the objectives of OO by having increased code reuse and decreased code maintenance, so as far as I am concerned my efforts have been a resounding success. So when someone tells me that I have failed simply because they don't like the way that I have achieved my results you must excuse me if I consider that person to be a candidate for the funny farm.
Had I come to learn about OOD and OOP without any prior experience with database applications, and had I been taught all that wild OOD theory then in all probability I would not have achieved the same level of success, not by a long chalk. This just tells me that OOD is either completely wrong, or just incompatible with database applications. If this is the case then surely it is a strong argument for giving OOD the elbow and sticking to the design methodology that is simpler and more reliable?
The big selling point of OOP is supposed to be that it gives you the ability to model the real world, but you have to be careful about which parts you model and how you model them. You do not need to model the whole of the real world, just those parts with which you wish to interface or interact. When it comes to writing database applications you have to realise that, as shown in Figure 4, you are not interacting with real world objects or entities at all, you are in reality only interacting with information about those real world objects, and that information exists as tables and columns in a relational database as shown in Figure 5.
Figure 4 - Database application does NOT interact with real world objects
")
As we are not interacting with real world objects it should be obvious that the operations which can be performed on a real world object then become totally irrelevant. We are only interacting with tables in a database, and guess what are the only operations which can be performed on a database table? Nothing more than Create, Read, Update and Delete. It does not matter how many tables you have in a database, or what information they hold, they are all manipulated using the same four operations.
Each table holds its data in exactly the same manner - in one or more columns. Each column has a particular type (character, integer, decimal, date, time, date+time, boolean, etc) and a size. Certain columns may be designated as primary keys, candidate keys or indexes which allow information in the database to be retrieved in an efficient manner. There are also foreign keys which show that a database table is related to another table, or even to itself. Each relationship is expressed as two tables being in a one-to-many or parent-child relationship. The process by which the information on real world objects or entities is organised into tables, columns, keys and relationships is known as Data Normalisation, and once this process is complete the real world objects become irrelevant as the software will never interact them in any way whatsoever, as shown in Figure 5:
Figure 5 - Database application interacts with tables in a database
")
It is also important to note that during the process of Data Normalisation the data for a real world object may need to be split across more than one table. Although these tables should be related in some way so that they may be joined together to produce a single set of data, it should be noted that each table can still be treated as a separate entity in its own right and can be accessed using the same CRUD operations as every other table. A table may have another table as its parent and at the same time have a third table as its child. Each parent may have parents of its own, and each child may have children of its own, but that does not matter. When an SQL query is created for a table the table may be examined on its own, or it may be JOINed with any number of other tables. In other words, the existence of a relationship does not place any restrictions on how a table may be accessed. A SELECT query may reference any number of tables, but an INSERT, UPDATE or DELETE query will only work on one table at a time.
Figure 6 shows an Entity Relationship Diagram (ERD) from part of my ERP application. This contains a dozen or so tables which are all related in one way or another. Despite the number and complexity of these relationships each of these tables can still be treated as a stand-alone entity and accessed in the same way as every other table in the database.
Figure 6 - ERD for Orders, Items and Item Features
")
Unlike OO theory where a has-a relationship is used as a reason to employ Object Composition to create a complex object, in relational theory there is no such thing as a complex table - a table is a table irrespective of how many relationships it may or may not have. For example, an ORDER_HEADER has ORDER_ITEMs, so in OO theory the ORDER_ITEM object is created as part of the ORDER_HEADER object and can only be accessed by going through the ORDER_HEADER object. No such situation exists in relational theory. Just because a table exists as the child in a parent-child relationship does not mean that I have to go through the parent to get to the child - I can reference the child as if it were a stand-alone entity without any relationships, or I can reference several related tables in the same query by incorporating one or more JOIN clauses.
Note also that the ORDER_ITEM table actually has two parents - ORDER_HEADER and PRODUCT - so in which of those two composite objects should it be included? If you say one then you will make it difficult to access it through the other. If you say both then you will be guilty of duplication. As relational databases do not support composite objects they have neither of these problems.
Using my framework I can build the same family of forms for every one of those tables in figure 6, and they would be perfectly usable transactions. Although these would the simplest and most basic of transactions, they would all share the same 6 Controller scripts, the same single View object for all HTML output, and the same 2 reusable XSL stylesheets. For more complex transactions I have created a library of Transaction Patterns. I have created an ERP application which contains over 2,500 transactions from this set of patterns, so I am not making false claims.
This is a common complaint from those who have been schooled in all that OO philosophy but who know absolutely nothing about databases and how to use them either effectively or efficiently. They refer to the database as a Persistence Store where persistence is described as:
Persistence is the ability of an object to survive the lifetime of the process in which it resides. This allows the object's state to be retained between its deactivation and subsequent re-activation.
They therefore expect the persistence mechanism to store and load their complex objects without having to bother with such things as tables and columns. They treat the whole idea of persistence as being nothing more than a mere implementation detail that can be left until last as it should have no effect on how the system is designed. What they want is an Object Oriented Database (OODBMS) instead of a Relational Database (RDBMS). Various organisations have written articles on how object state should be persisted, but nobody has yet invented something that is good enough to take the place of the relational database. Unfortunately OO databases, while being great in theory, have not proved to be so great in practice, so are only used in small niche markets.
By continuing to design their software to follow the concepts of OO theory, then finding out that the only usable database is relational and not OO, they are then left with this problem known as Object-Relational Impedance Mismatch. Instead of eliminating the problem they prefer to patch over it by employing a separate piece of software known as an Object-Relational Mapper (ORM) as an intermediary between the two conflicting structures. I personally think that Object-Relational Mappers are Evil, and I am not the only one to share this opinion as shown by the book title in Figure 7:
Figure 7 - Book for ORM fanatics
")
When programmers complain that relational databases are not Object Oriented I have to answer with "It depends on your definition of OO". Considering that Nobody Agrees On What OO Is and nobody can agree on what makes a language OO or not, it can be said (and I'm just about to say it) that relational databases do actually share some of the major concepts of OO theory, but they simply implement them in a slightly different way. In the following paragraphs I will examine several of these major concepts one by one and show you what I mean.
I disagree. In this definition it says that a class is a blueprint or prototype from which objects are created. If you look at the Data Definition Language (DDL), the CREATE TABLE script, for a database table you should see that this acts as a blueprint for every record that will be written to that table. So if they are both blueprints then they both serve the same purpose but in a different way.
I disagree. In OOP an object is an instance of a class, and in a database a record in a table is an instance of that table's DDL. So they are both instances of their respective classes or blueprints.
I disagree. If you look at this description of Encapsulation you will see that it is nothing more than the act of placing data and the operations that perform on that data in the same class. I have already shown that databases do in fact have their equivalent to classes but what about the operations? A competent programmer will immediately tell you that you never have to specify the operations that can be performed on individual tables as every table is automatically subject to the same operations - Create, Read, Update and Delete.
I disagree. Inheritance is merely a technique for sharing the methods and properties of a superclass with a subclass. It is implemented using the extends keyword as in subclass extends superclass and produces a class hierarchy like that shown in Figure 8:
Figure 8 - A Superclass-Subclass relationship
")
Note that a superclass can be shared by more than one subclass, and a subclass can have subclasses of its own.
The method whereby common data can be "shared" in a database is provided by a foreign key on a child table which links to the primary key of a parent table, as shown in Figure 9:
Figure 9 - A Parent-Child relationship
")
This may also be known as a One-to-Many relationship as an instance of the Parent (One) can be related to more than one instance of the Child (Many).
If inheritance is used incorrectly it can cause problems, which causes some people to say that inheritance should not be used at all. This is why they created the principle "favour composition over inheritance". In a lot of tutorials on OO I see examples of class hierarchies created just because something IS-A type of something else. For example, "dog" is a class, but because "alsatian", "beagle" and "collie" are regarded as types of "dog" they are automatically represented as subclasses. This results in a structure similar to that shown in Figure 10:
Figure 10 - hierarchy of "dog" classes
")
With this approach you cannot introduce a new type (breed or variety) of dog without creating a new subclass/subtype which uses the "extends" keyword to inherit from the superclass/supertype. In some people's minds subtyping is not the same as inheritance, but this depends entirely on the language which you are using. This idea is a relic of programming languages from a much earlier age. In the Gang of Four book, which was published in 1994 and therefore not written with PHP in mind, it states the following:
Specifying Object Interfaces
Every operation declared by an object specifies the operation's name, the objects it takes as parameters, and the operation's return value. This is known as the operation's signature. The set of all signatures defined by an object's operations is called the interface to that object. An object's interface characterises the complete set of requests that can be sent to the object. Any request that matches a signature in the object's interface may be sent to the object.
A type is a name used to denote a particular interface. An object may have many types, and widely different objects can share a type. Part of an object's interface may be characterised by one type, and other parts by other types. Two objects of the same type need only share parts of their interfaces. Interfaces can contain other interfaces as subsets. We say that a type is a subtype of another if its interface contains the interface of its supertype. Often we speak of a subtype inheriting the interface of its supertype.
...
Class versus Interface Inheritance
It is important to understand the difference between and object's class and its type.
An object's class defines how the object is implemented. The class defines the object's internal state and the implementation of its operations. In contrast, and object's type only refers to its interface - the set of requests to which it can respond. An object can have many types, and objects of different classes can have the same type.
This is irrelevant in PHP as classes and objects do not have different types. You cannot assign a "type" to a class, and if you use the gettype() function after you have instantiated a class into an object the result will always be "object", so testing for an object's "type" is a waste of time as different objects do not have different "types". There are other functions you may use to identify the class from which an object was instantiated, such as get_class(), get_parent_class() and is_subclass_of(). Personally I have no use for any of these as every concrete class in my Business/Domain layer IS-A database table because they all inherit from the same abstract table class. This means that using the words "type", "supertype" and "subtype" has no special meaning in PHP. They are the same as "class", "superclass" and "subclass".
Just as "type" and "subtype" are meaningless in PHP they are also meaningless in a database as it is simply not done to create a separate table for each subtype when they exist as rows in the same table. If each subtype does not require its own table then why should it require its own class?
In a database the DOG entity would have its own table, and in my software each table, because it has its own business rules, would have its own class. Each table can handle multiple rows, so its class should do so as well. In a database the idea of being able to split the contents of the DOG table into different types, breeds or varieties would not involve separate tables, it would simply require an extra column called DOG-TYPE which would be just one of the attributes or properties that would be recorded for each dog. If there is no need for a separate table for each DOG-TYPE I can see no reason to have a separate subclass for each DOG-TYPE.
If there were additional attributes to go with each DOG-TYPE then I would create a separate DOG-TYPE table to record these attributes, and make the DOG-TYPE column of the DOG table a foreign key which points to the DOG-TYPE column of the DOG-TYPE table, which would be its primary key. This would produce the structure shown in Figure 11:
Figure 11 - structure of "dog" tables
")
With this design all the attributes of a particular type/breed of dog are stored on the DOG-TYPE table, so instead of a separate subclass for each DOG_TYPE I would have a separate row on the DOG-TYPE table. When reading from the DOG table you can include a JOIN in the SQL query so that the result combines the data from both tables. This is how you can "inherit" attributes in a database. The introduction of a new type of dog requires no more effort than adding a record to the DOG-TYPE table. There are no changes required to the software, no new classes, no new screens, no new database tables, no nothing. From a programmer's point of view this simple 2-table structure is far easier to deal with than an unknown number of subclasses.
There may be cases where the number of different "types" is fixed, but the difference between them are quite significant and therefore require different table structures, in which case I would use a structure similar to what is shown in Figure 12:
Figure 12 - hierarchy of tables (1)
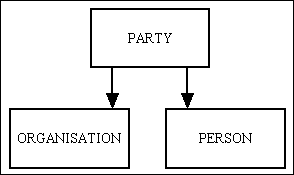
Here a PARTY can either be an ORGANISATION or a PERSON. The PARTY table holds the data which is common to both, while the other tables hold the data which is specific to that type. Now, if both ORGANISATION and PERSON can be broken down into different types I would use the structure shown in Figure 13:
Figure 13 - hierarchy of tables (2)
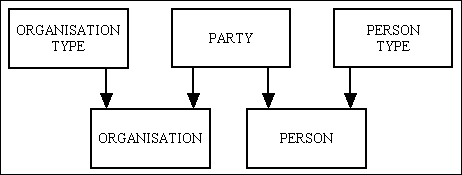
You should therefore be able to see that although the mechanisms are different the results are the same.
This topic is also discussed in Subclasses vs Subtypes.
I disagree. Polymorphism is nothing more than the ability for several classes to share the same methods or operations. When you consider the fact that methods are not defined for each table in a database for the simple reason that the same set of methods - INSERT (create), SELECT (read), UPDATE and DELETE - is common across all tables, it is plain to see that all tables automatically share exactly the same methods. For example, you can take the following SQL query:
SELECT * FROM <tablename>;
and insert any value for <tablename> and that operation will produce different results. That meets the definition of polymorphism does it not?
I disagree. The definition of dependency is nothing more than the basic relationship among objects, and a relational database was specifically designed to handle the relationships between tables by using a foreign key on a child table to link back to the primary key of its parent table.
The only dependency in a relational database is that the value in a foreign key should contain a primary key of an entry in the parent table.
I disagree. They do exist, but with a different name - relationships.
In OO literature these things called "associations" are described in several different ways:
UML modelling technique in Wikipedia describes an association in OOP as follows:
An association represents a semantic relationship between instances of the associated classes. The member-end of an association corresponds to a property of the associated class
Object Association in Wikipedia has the following description:
In object-oriented programming, association defines a relationship between classes of objects that allows one object instance to cause another to perform an action on its behalf. This relationship is structural, because it specifies that objects of one kind are connected to objects of another and does not represent behaviour.
In generic terms, the causation is usually called "sending a message", "invoking a method" or "calling a member function" to the controlled object. Concrete implementation usually requires the requesting object to invoke a method or member function using a reference or pointer to the memory location of the controlled object.
HAS-A in Wikipedia has the following description:
In database design, object-oriented programming and design, has-a (has_a or has a) is a composition relationship where one object (often called the constituted object, or part/constituent/member object) "belongs to" (is part or member of) another object (called the composite type), and behaves according to the rules of ownership. In simple words, has-a relationship in an object is called a member field of an object. Multiple has-a relationships will combine to form a possessive hierarchy.
As you can see there are several different descriptions of what associations are and how they should be dealt with. The typical way that I see other programmers implementing these "rules" is as follows:
Fortunately for me I was not aware of these "rules" when I switched to programming with an OO-capable language as I already had 20 years of experience with designing and building database applications in several non-OO languages. This experience taught me to understand how databases work and to write code which works with the database. The idea of writing code which adheres to some obscure formula then trying to force the database to follow this formula never struck me as being a viable option.
While novice OO programmers are taught to follow the rules of "HAS-A" in order to deal with relationships I did not know of this rule, so I allowed my experience and intuition to point me to a more practical path. This is discussed in the following:
This is also summarised in Object Associations are EVIL.
This type of association implies that the contained class cannot exist independently of the container. If the container is destroyed, the child is also destroyed.
This topic is discussed in OOP for Heretics - Object Composition.
This type of association implies that the contained class can exist independently of the container. If the container is destroyed, the child is not destroyed as it can exist independently of the parent.
This topic is discussed in OOP for Heretics - Object Aggregations.
I have been told many times that an object should only reference a single database table and should only handle one row from table, but this isn't how relational databases work, so I ignore it. This bad advice also leads to the N+1 SELECT Problem, and I am in the business of providing solutions, not problems. My solution to this problem depends on the circumstances. Each of my HTML screens has a structure which includes one or more zones for application data, so my solution depends on the number of zones:
This method causes multiple reads and is an example of the N+1 SELECT Problem. Imagine the following scenario: I wish to display 10 rows from the CHILD table, and in each row I wish to display a value from the PARENT table. The first part can be satisfied a query such as:
SELECT * FROM child LIMIT 10 OFFSET 0;
After those 10 rows have been retrieved from the database it is then necessary to iterate through those rows and issue another query to retrieve data from the PARENT table for the current row. This "solution" will therefore require one query to access the CHILD table and ten queries to access the PARENT, so for 10 rows it will require 10+1 queries. This is why it is known as the "N+1" problem.
This can be done in my framework by putting code into the _cm_getForeignData() method similar to the following:
function _cm_getForeignData ($fieldarray) // Retrieve data from foreign (parent) tables. { if (!empty($fieldarray['prod_cat_id']) and empty($fieldarray['prod_cat_desc'])) { // get description for selected entry $dbobject = RDCsingleton::getInstance('product_category'); $dbobject->sql_select = 'prod_cat_desc'; $foreign_data = $dbobject->getData("prod_cat_id='{$fieldarray['prod_cat_id']}'"); // merge with existing data $fieldarray = array_merge($fieldarray, $foreign_data[0]); } // if return $fieldarray; } // _cm_getForeignData
Anyone who knows SQL will know that the most efficient way to retrieve all this data is from a single query that contains a JOIN clause, as in the following:
SELECT child.*, parent.foobar FROM child LEFT JOIN parent ON (parent.pkey=child.fkey) LIMIT 10 OFFSET 0;
Although it is possible to manually adjust the query which is generated by placing the relevant code in the _cm_pre_getData() method, it is also possible to get the framework to automatically adjust the query by specifying which columns should be retrieved from which foreign tables using the mechanism described in Using Parent Relations to construct sql JOINs.
Some screens may have more than one zone into which application data can be displayed, such as that shown in Figure 16:
The top zone is used to display a single row from the PARENT table while the bottom zone is used to display multiple rows from the CHILD table which are related to that PARENT. Conventional wisdom states that a Controller can only ever access a single Model (who invented THAT stupid rule?) which means that the data for both zones must be obtained from a single object. Using table names of FOOBAR and SNAFU instead of PARENT and CHILD this would require code similar to the following:
$dbobject = new foobar; $foobar_data = $dbobject->getData_from_Foobar($where); $snafu_data = $dbobject->getData_from_Snafu($where);
This is wrong on so many levels:
By ignoring conventional wisdom and having the Controller communicate with a separate object for each zone, there is no need to construct composite objects, no need for custom methods, no need for custom controllers, no loss of reusability, and no loss of polymorphism. In my framework I have a LIST 2 pattern which has two zones call OUTER (parent) and INNER (child) which contains code similar to the following:
require "classes/$outer_table.class.inc"; $dbouter = new $outer_table; $outer_data = $dbouter->getData($where); $inner_where = array2where($outer_data, $dbouter->getPkeyNames(), $dbouter); require "classes/$inner_table.class.inc"; $dbinner = new $inner_table; $inner_data = $dbinner->getData($inner_where);
This code will use values for $outer_table and $inner_table which are passed down from one of the many component scripts such as in the following:
$outer_table = 'foobar'; // name of outer (parent) table $inner_table = 'snafu'; // name of inner (child) table $screen = 'snafu.list2.screen.inc'; // file identifying screen structure require 'std.list2.inc'; // activate page controller
If you are awake you should notice that I can have multiple copies of this script where each copy can specify different values for $outer_table and $inner_table, but the contents of std.list2.inc will remain unchanged. This means that I can use the std.list2.inc Controller with ANY combination of tables in the database (provided that they are related, of course). THAT is a prime example of reusability through polymorphism, and a prime example of what is lost by using custom methods in your Models which in turn requires custom controllers to call those custom methods.
If a page controller contains the following code:
$table_id = 'foobar'; ..... require "classes/$table_id.class.inc"; $dbobject = new $table_id; $fieldarray = $dbobject->insertRecord($_POST);
what do you think happens? If you look at this description of the insertRecord() method you should see that it actually calls a series of sub-methods to perform a series of procedures in a specific sequence. If any of these sub-methods detects an error it adds an error message to the $this->errors array and exits back to the Controller, which causes the insert operation to be abandoned and the error message(s) to be displayed on the user's screen. Among the list of sub-methods is _cm_post_insertRecord() which can be filled with custom code similar to the following:
function _cm_post_insertRecord ($fieldarray) // perform custom processing after database record has been inserted. { $dbobject = RDCsingleton::getInstance('other_table'); $other_data = $dbobject->insertRecord($fieldarray); if ($dbobject->errors) { $this->errors = array_merge($this->errors, $dbobject->getErrors()); } // if return $fieldarray; } // _cm_post_insertRecord
Note that it is not necessary to filter the contents of $fieldarray before it is passed to the new object as all filtering and validation will be handled inside the object. It is not necessary to specify any columns by name, either for the primary table or the secondary table, as all column names and their associated values are contained within $fieldarray. If any errors are generated the entire operation will be abandoned which will include a rollback to undo any updates which have happened so far in the current task.
It is possible for this method to perform any number of operations on any number of table objects, and it is possible for these secondary objects to have additional processing of their own.
There is no such thing as a single way to write cost-effective software which is easy to read, easy to understand and easy to maintain. What some people try to promote as the "one true way" I have learned to avoid like the plague as the results simply do not measure up. I have mentioned some of these questionable practices in the preceding paragraphs, and below I present a summary for your amusement and edification.
OOD/OOAD may be relevant when you are designing software which will interface or interact with objects in the real world, but if you are designing a system which is going to do nothing more than interact with tables in a database then the design of the database, following the rules of Data Normalisation, should be the starting point. This avoids the following problems:
All the above would be greatly hampered if you did not have access to a development framework which was specifically designed to help build and then run database applications. Fortunately I do because I wrote it.
Too many programmers are told to hide the fact that they are communicating with a relational database, and this encourages them to avoid learning about how they work and how they can be used effectively. This encouraged Martin Fowler, who is the author of Patterns of Enterprise Application Architecture (PoEAA) to say the following in his article Domain Logic and SQL:
Many application developers tend to treat relational databases as a storage mechanism that is best hidden away. Frameworks exist who tout the advantages of shielding application developers from the complexities of SQL.
Yet SQL is much more than a simple data update and retrieval mechanism. SQL's query processing can perform many tasks. By hiding SQL, application developers are excluding a powerful tool.
In his article OrmHate the also says the following:
I often hear people complain that they are forced to compromise their object model to make it more relational in order to please the ORM. Actually I think this is an inevitable consequence of using a relational database - you either have to make your in-memory model more relational, or you complicate your mapping code. I think it's perfectly reasonable to have a more relational domain model in order to simplify [or even eliminate] your object-relational mapping.
Note that the words or even eliminate are mine. Later in the same article he also says:
To use a relational model in memory basically means programming in terms of relations, right the way through your application. In many ways this is what the 90's CRUD tools gave you. They work very well for applications where you're just pushing data to the screen and back, or for applications where your logic is well expressed in terms of SQL queries. Some problems are well suited for this approach, so if you can do this, you should.
So if Martin Fowler says that it's OK to use a relational model in memory and so avoid having to use a complicated mapper then who are you to argue?
In his article The power of table-oriented programming Fredrik Bertilsson has this to say:
This article has described a non-mainstream solution for database programming. The solution resembles database programming before the object-oriented era. But there is one big difference: it utilizes the full power of the object-oriented programming language. There does not need to be any impedance mismatch between the use of a relational database and an object-oriented programming language.
.....
The table-oriented programming model allows the application source code to be aware of the actual database structure instead of hiding it in a mapping layer deep in the application stack. Many enterprise applications have a lot of CRUD-related (create, read, update, delete) logic, and developing CRUD functionality is much simpler if the database structure is not hidden.
One argument for having an object model that doesn't correspond with the actual database structure is that the business logic should remain the same even if the database structure changes. But this argument neglects the fact that much business logic is implemented in a relational database schema. Changing the database schema will, by definition, also change the business logic.
Most OO programmers fail to realise that the effort required to hide the database structure is compounded by the effort required to deal with the fact that it is hidden. As Fredrik Bertilsson says:
One consequence of this refusal to model a relational database's real structure is an extra layer of abstraction. Table, columns, and foreign keys must be mapped to classes, properties, and associations. In most cases, there is one class for each table, one property for each column, and one association for each foreign key. Besides, SQL must be reinvented (Hibernate Query Language (HQL), JDO-QL, EJB-QL, etc). Why bother adding this extra layer? It adds complexity and provides few additional features.
The idea of having one class per database table is not as unacceptable as some people might think. In his blog post Decoupling models from the database: Data Access Object pattern in PHP Jani Hartikainen makes this opening statement:
Nowadays it's a quite common approach to have models that essentially just represent database tables.
Although there are technical differences between our two implementations - such as the fact that I don't have a separate DAO for each table, and I don't have a separate class property for each table column - the underlying concept is the same.
In OO theory class hierarchies are the result of identifying "IS-A" relationships between different objects, such as "a CAR is-a VEHICLE", "a BEAGLE is-a DOG" and "a CUSTOMER is-a PERSON". This causes some developers to create separate classes for each of those types where the type to the left of "is-a" inherits from the type on the right. This is not how such relationships are expressed in a database, so it is not how I deal with it in my software. Each of these relationships has to be analysed more closely to identity the exact details. Please refer to Using "IS-A" to identify class hierarchies for more details on this topic.
Objects in the real world, as well as in a database, may either be stand-alone, or they have associations with other objects which then form part of larger compound/composite objects. In OO theory this is known as a "HAS A" relationship where you identify that the compound object contains (or is comprised of) a number of associated objects. There are several flavours of association:
Please refer to Using "HAS-A" to identify composite objects for more details.
Without exception every article I have ever read on the internet insists on having a separate class property for each column in the database. Anyone who was worked with databases knows that SQL deals with sets of data, which can include any number of columns from any number of rows, so deconstructing a dataset into its individual components is, in my humble opinion, going too far. When the user presses the SUBMIT button on an HTML form all the data from that form is made available to the PHP script in the form of the $_POST array, and this array can be passed to an object with a single command, as shown in the following example:
$result = $dbobject->insertRecord($_POST);
It is just as easy to refer to an individual column with $this->fieldarray['fieldname'] as it is with $this->fieldname, so nothing is lost.
When reading from the database the result of executing a SELECT statement will always be an associative array containing values for whatever columns were selected, as shown in the following example:
$fieldarray = $dbobject->getData($where);
When the DAO passes data back to the Model there is no need for code which references column names individually, which makes the code reusable across all tables instead of specific to a single table.
The simple mechanism of passing data around in a single $fieldarray instead of column by column has a very useful side-effect in that the $fieldarray can sometimes contain data for columns which do not actually exist on that table (such as through SQL JOINs), or sometimes have columns missing. When passing data between objects in a single $fieldarray variable the passing mechanism never has to know the contents of the array, so does not have to deal with extra or missing columns.
The following code sample exhibits tight coupling:
<?php $dbobject = new Person(); $dbobject->setUserID ( $_POST['userID' ); $dbobject->setEmail ( $_POST['email' ); $dbobject->setFirstname ( $_POST['firstname'); $dbobject->setLastname ( $_POST['lastname' ); $dbobject->setAddress1 ( $_POST['address1' ); $dbobject->setAddress2 ( $_POST['address2' ); $dbobject->setCity ( $_POST['city' ); $dbobject->setProvince ( $_POST['province' ); $dbobject->setCountry ( $_POST['country' ); if ($dbobject->updatePerson($db) !== true) { // do error handling } ?>
Here is an example of my code which exhibits loose coupling:
<?php require_once 'classes/$table_id.class.inc'; // $table_id is provided by the previous script $dbobject = new $table_id; $result = $dbobject->updateRecord($_POST); if ($dbobject->errors) { ... error handling } // if ?>
This is explained in more detail in Don't use getters and setters for user data and Getters and Setters are EVIL.
In his article Objects as Contracts for Behaviour Mathias Verraes argues against the following comment:
Objects should just be bags of state and nothing more. An invoice does not pay itself. An appointment does not reschedule itself.invoice.pay(anAmount)andappointment.reschedule(aDate)do not match the real world. Something on the outside drives the action. A service of some kind should do the paying and the rescheduling, and then update the state of those objects:invoice.setPaidAmount(anAmount)andappointment.setDate(aDate). By consequence, not in the objects, but the services should contain the business logic.
His argument is stated as follows:
Of course invoices do not pay themselves, but that's not what an object model is trying to do. An invoice exposes the behaviour of being able to be paid. That ability is in fact essential to what it means to be an invoice. The behaviour is an inherent property of an invoice. If an invoice doesn't have the ability of being paid, there's no point in issuing invoices at all. In other words, the contract of an invoice object declares that its interface includes payment as a feature. Its promise to the outside world is that it allows an outsider to pay for it.
Encapsulation of state and behaviour is the core idea behind objects.
Just because an invoice can be paid does not mean that the invoice object itself must have a "PayMe" method. This method would be unique to this class, and this in turn would require a unique controller to call that method. By doing this you have instantly removed any reusability from that controller as it can only be used on an object which contains that method. By using specific methods instead of generic methods you have disabled any opportunity for reuse via polymorphism.
How is it possible to achieve these results without using specialised methods? You have to remember that in a database application the entities called INVOICE and APPOINTMENT are both database tables, and the only operations that can be performed on a database table are Create, Read, Update and Delete. In my framework these operations are built into my abstract table class which is inherited by every concrete table (Model) class. Every one of my 40 page controllers communicates with its Model by using these generic methods, which means that every one of those page controllers is capable of being used with any of my 300+ table classes. Thus by opening up the door to polymorphism I have created a huge amount of reusable code, and as this is supposed to be one of the objectives of OOP it must be a good idea.
How is it possible to perform these operations by calling generic methods? You should realise that in an application each use case is implemented as a user transaction (task) which can be selected from a menu. Each task consists of a Controller which calls a Model which in turn calls a DAO to update the database. So for each user transaction you need to identify exactly what operations on what database tables are needed to achieve the desired result.
In order to implement the use case "add a payment to an invoice" it is not as simple as updating a single column in the INVOICE table. In a properly designed system you must allow for payments of different types (credit card, cheque, etc). You must also be able to deal with partial as well as full payments, and provide the ability to either void or refund a payment. This means that all payments are held on their own PAYMENT table while the invoice balance - the difference between the invoice amount and any payments - is held on the INVOICE table. In order to complete this use case the user transaction must achieve the following:
Point #1 can be done by creating a task which combines the standard ADD 1 pattern and the PAYMENT table. This will use the generic insertRecord() method to add a record to the PAYMENT table, such as in the following:
$table_id = 'payment'; ..... require "classes/$table_id.class.inc"; $dbobject = new $table_id; $result = $dbobject->insertRecord($_POST); if ($dbobject->errors) { $errors = array_merge($errors, $dbobject->errors); $dbobject->rollback(); } else { $dbobject->commit(); } // if
Point #2 can be achieved by inserting the following code into the _cm_post_insertRecord() method of the PAYMENT class:
function _cm_post_insertRecord ($fieldarray) // perform custom processing after database record has been inserted. { $dbobject = RDCsingleton::getInstance('invoice'); $pkey['invoice_id'] = $fieldarray['invoice_id']; $result = $dbobject->updateRecord($pkey); if ($dbobject->errors) { $this->errors = array_merge($this->errors, $dbobject->errors); } // if return $fieldarray; } // _cm_post_insertRecord
You may notice that this code does not actually identify which columns on the INVOICE table need to be updated with what values. This is because the updateRecord() method contains a call to the _cm_pre_updateRecord() method, and this method in the INVOICE class contains code similar to the following:
function _cm_pre_updateRecord ($fieldarray) // perform custom processing before database record is updated. { $where = array2where($fieldarray, $this->getPkeyNames()); $dbobject = RDCsingleton::getInstance('payment'); $fieldarray['total_paid'] = $dbobject->getCount("SELECT SUM(payment_amount)) FROM payment WHERE $where"); $fieldarray['balance'] = $fieldarray['invoice_amount'] - $fieldarray['total_paid']; return $fieldarray; } // _cm_pre_updateRecord
Notice that I do not bother with a special updateBalance() method as I want the balance to be automatically updated in every update operation, and this can be done with the generic updateRecord() method.
In order to implement the use case "reschedule an appointment" this could be as simple as updating the appointment_date column on the APPOINTMENT table, in which case all you need to do is create a task which combines the standard UPDATE 1 pattern and the APPOINTMENT table. Note that this will allow any column except for the primary key to be updated.
When it comes to performing the common CRUD operations on different database tables, such as Customer, Product and Invoice, I have seen too many implementations using method names which include the name of the object such as the following:
This approach is bad because it creates tight coupling between the Controller and the Model and makes it impossible to use a Controller with any other Model. It was obvious to me from the outset that the end result of each of those operations was to Create/Read/Update/Delete a record in the database table for which the object was responsible, so my approach has always been to use generic methods such as the following:
Not only can those same methods be used on those 3 table classes, they can be used used on any of the 300 classes in my application.
By working with the fact that I am updating a relational database, and breaking down each user transaction into specific database operations, I am able to perform each of those operations with a combination of pre-written and reusable generic code plus the addition of custom code in the relevant custom methods. This achieves the necessary results, but with far less effort, so how can it possibly be wrong?
Another practice in "proper" OOP which raised a red flag as soon as I saw it, such as in How dynamic finders work and PHP ActiveRecord Finders, was the use of specialist "finder" methods for database queries, such as:
The idea of creating such methods in my software never occurred to me for the simple reason that they don't exist in SQL. In order to select particular subsets of data in SQL all you need do is specify a WHERE clause in the SELECT statement, and this clause is nothing more than a simple string into which can be inserted a myriad of possibilities, such as the following:
field1='value1' field1='value1' AND field2='value2' (field1='value1' AND field2='value2') OR (field1='value11' AND field2='value12') OR (...) field1='value1' AND field2 [NOT] LIKE 'value2%' field1='value1' AND field2 IS [NOT] NULL field1 IN (SELECT ...) [NOT} EXISTS(SELECT ....) field1 BETWEEN 3 AND 12 ... et cetera, et cetera
This is why my framework contains only one method to retrieve data:
$array = $dbobject->getData($where);
The SELECT statement may be customised further by using any combination of the following:
$dbobject->sql_select = ('...'); $dbobject->sql_from = ('...'); $dbobject->sql_groupby = ('...'); $dbobject->sql_having = ('...'); $dbobject->sql_orderby = ('...'); $dbobject->setRowsPerPage(10); // used to calculate LIMIT $dbobject->setPageNo(1); // used to calculate OFFSET
By using a single $where argument it is therefore possible to specify anything which the database will accept, and because it is a simple string it is easy to view and modify its contents.
This wikipedia article contains the following description:
In software engineering, a design pattern is a general reusable solution to a commonly occurring problem within a given context in software design. A design pattern is not a finished design that can be transformed directly into source or machine code. It is a description or template for how to solve a problem that can be used in many different situations. Patterns are formalized best practices that the programmer must implement themselves in the application.
This is the description of a pattern:
A pattern, apart from the term's use to mean "Template", is a discernible regularity in the world or in a man made design. As such, the elements of a pattern repeat in a predictable manner
This is the description of a template:
- A physical object whose shape is used as a guide to make other objects.
- A generic model or pattern from which other objects are based or derived.
- (molecular biology) A macromolecule which provides a pattern for the synthesis of another molecule.
- (computing) A partially defined class, that can be instantiated in a variety of ways depending on the instantiation arguments.
My biggest problem with design patterns is that they do not actually provide any reusable solutions. They simply describe a description of a solution which you then have to code yourself each and every time. Where is the reusability in that? Where are the savings? I am not the only one to notice this anomaly. The following statement can be found in PatternBacklash:
In software engineering, duplication of something is often considered a sign that more abstraction or factoring is needed. Duplication should generally be refactored into one or fewer spots to simplify the code and localize changes to one or fewer spots. In other words, why do patterns have to be duplicated instead of just referenced for each usage? Do GOF patterns represent unnecessary duplication?
Every developer is taught that he must use design patterns, so he spends time in reading about patterns or talking about patterns, and when designing software starts by listing all the fashionable patterns that he should use with the aim of using as many patterns as possible. This is totally the wrong approach. In the article How to use Design Patterns there is this quote from Erich Gamma, one of the authors of the GOF book:
Do not start immediately throwing patterns into a design, but use them as you go and understand more of the problem. Because of this I really like to use patterns after the fact, refactoring to patterns.
One comment I saw in a news group just after patterns started to become more popular was someone claiming that in a particular program they tried to use all 23 GoF patterns. They said they had failed, because they were only able to use 20. They hoped the client would call them again to come back again so maybe they could squeeze in the other 3.
Trying to use all the patterns is a bad thing, because you will end up with synthetic designs - speculative designs that have flexibility that no one needs. These days software is too complex. We can't afford to speculate what else it should do. We need to really focus on what it needs. That's why I like refactoring to patterns. People should learn that when they have a particular kind of problem or code smell, as people call it these days, they can go to their patterns toolbox to find a solution.
The GOF book actually contains the following caveat:
Design patterns should not be applied indiscriminately. Often they achieve flexibility and variability by introducing additional levels of indirection, and that can complicate a design and/or cost you some performance. A design pattern should only be applied when the flexibility it affords is actually needed.
This sentiment is echoed in the article Design Patterns: Mogwai or Gremlins? by Dustin Marx:
The best use of design patterns occurs when a developer applies them naturally based on experience when need is observed rather than forcing their use.
Another problem I have found with too many programmers is that they fail to realise that each design pattern is only supposed to provide benefits in a particular situation, or to be a particular solution to a particular problem, and if that situation does not exist in your code then implementing that solution may not provide any benefits at all. On the contrary, it may actually provide negative benefits in the form of unnecessary code which is hard to read and therefore hard to understand and maintain. This does not stop these numpties from using certain design patterns at every opportunity instead of only when the circumstances are appropriate. A typical case is with Dependency Injection: despite me saying that this technique should only be used when appropriate, there are numpties out there who do not understand what "appropriate" means and who insist that it should automatically be used for every dependency regardless of the circumstances.
The idea that using patterns which were documented by experts will enable any novice programmer to write code as good as that written by those experts is a complete fallacy. In the blog post When are design patterns the problem instead of the solution? the author T. E. D. wrote:
My problem with patterns is that there seems to be a central lie at the core of the concept: The idea that if you can somehow categorize the code experts write, then anyone can write expert code by just recognizing and mechanically applying the categories. That sounds great to managers, as expert software designers are relatively rare. The problem is that it isn't true.
The truth is that you can't write expert-quality code with "design patterns" any more than you can design your own professional fashion designer-quality clothing using only sewing patterns.
I do not use design patterns. By that I mean that I do not read about them then try to implement them. I simply write code that works, and if a pattern appears in my code then it's more by luck than by design, a mere coincidence. When I rewrote my development framework in PHP one of my first objectives was to implement the 3-Tier Architecture which I had encountered in my previous language. I had personally witnessed the advantages of this architecture over its earlier 1-Tier and 2-Tier alternatives, so I did not need to be told by some self-styled guru that it was a good idea. It was not until several years later when a colleague pointed out to me that because I had split my Presentation layer into two separate parts which matched the description of the View and the Controller, with the Business layer playing the part of the Model, that I had also implemented the Model-View-Controller design pattern. When I published an article on what I had done I was immediately told that my implementation was wrong, but I didn't care.
The only design pattern that I have ever read about and then implemented is the Singleton pattern, but being a heretic my implementation is totally different to everyone else's and therefore wrong. Do I care? Not one iota. My implementation does not have the problems reported by others, so I do not consider it to be in the slightest bit evil at all.
I prefer to use Transaction Patterns instead of design patterns for the simple reason that they give me access to pre-coded designs which I can quickly turn into runnable components simply by saying "Match this Transaction Pattern with that database table" without the need to write any code. These are genuine reusable patterns, not simply descriptions of patterns, as I don't have to write a fresh implementation each time I want to use one.
For more of my thoughts on the thorny subject of design patterns you can read these articles:
As far as I am concerned these are just a collection of artificial rules which were dreamed up by members of the let's-make-it-more-complicated-than-it-really-is-just-to-prove-how-clever-we-are brigade. They may sound good in theory but in practice they are not. My biggest problem with them is that they are badly written and imprecise, which leaves them open to enormous amounts of interpretation, over-interpretation and mis-interpretation. I have written a separate article called Not-so-SOLID OO Principles which can be summed up as follows:
What is a "single responsibility"? How do you know when a component has too many responsibilities and needs to be split into smaller components? How do you know when to stop splitting? Despite Robert C. Martin clearly stating that the three areas of "responsibility" or "concern" which should be separated are GUI logic, business logic and database logic, there are far too many programmers who continue the separation process to ridiculous extremes. My framework is split into 3 separate layers, and that provides all the separation I need, so I see no justification in splitting it further.
This principle does not properly identify what problem(s) it is trying to solve, and as far as I can see all it does is introduce new problems. It is therefore less problematic to ignore this principle completely.
This entire principle is irrelevant if you only inherit from an abstract class, as I do in my framework.
This principle is only relevant if you use the keywords "interface" and "implements". These keywords are both optional and unnecessary in the PHP language, and as I choose not to use them in my framework this principle is consequently completely irrelevant.
In the first place the common description of this principle, which is "High-level modules should not depend on low-level modules. Both should depend on abstractions. Abstractions should not depend on details. Details should depend on abstractions."
is, in my humble opinion, total garbage. In the second place the author of this principle gives an example in the "Copy" program where its application would be appropriate and provide genuine benefits, but far too many programmers insist on applying this principle in all circumstances whether they are appropriate or not. I have found a place in my framework where I can actually make use of DI, but in those places where it is not appropriate I do not use DI at all.
Although not in SOLID, here is another common principle which I choose to ignore:
This is often stated as "favour composition over inheritance" and is intended to deal with those situations where the over use of inheritance causes problems. As I do not have deep hierarchies, only ever inheriting from a single abstract class, I do not have this problem which means that I don't need this solution.
There is a very old proverb which states The Proof of the Pudding is in the Eating which roughly means that it does not matter how much effort went into either creating or following the recipe, it is how the final product tastes that matters. It does not matter to me how much effort has been put into modern OO theory, or how many articles and books have been written to show how this theory can be put into practice. I consider the latest theories to be seriously flawed in that they may be fine in theory but they do not measure up in practice. I also consider that most of the implementations of these theories are flawed, so by putting the two together this means that all the flawed implementations of those flawed theories are doubly flawed. How can I say this? Simple. By ignoring all these flawed theories and using my own experience and common sense I have come up with a method which produces cost effective software with far less effort, lower costs, shorter timescales and more features than my rivals, and which customers are willing to buy. That last point is the most important. I write software to impress my customers, NOT to impress other developers with the purity of my design and implementation. I do not follow their artificial rules simply because I can achieve superior results by ignoring those rules. If those rules are supposed to encourage the building of good software then I'm afraid they have failed - unless in your world you spell the word "good" with the letters "C", "R", "A" and "P".
By continuing to follow my own approach and ignoring the "advice" of my critics I have managed to create a development framework which enables me to build database applications at a faster rate than any of the rival frameworks. When I say "faster" I mean that, starting with nothing more that a table's schema in the database, I can import that table's structure into the Data Dictionary, run the EXPORT process it to create the class file, then generate the scripts for the family of forms within 5 minutes and then run them without the need to write a single line of code - no PHP, no HTML and no SQL.
The framework has four modules (which I prefer to call subsystems):
The Data Dictionary is used to create application components while the RBAC system is used to run those components. The Audit Logging system is used to both record and view all changes made to the database while the Workflow system can be used to automatically start a second task when the first task has been completed.
Some people tell me that by not following their rules that my code must automatically become an unmaintainable pile of poo, but they could not be more wrong. If you examine the levels of reusability that I have achieved you should see that all the standard behaviour is covered by code within the abstract table class, the page controllers and the View objects. These are all reusable components which are part of the framework and do not have to be written or modified by any developer. All application Model classes only need contain additions to the standard functionality which means that I can make changes to the standard functionality without having to make any changes to any application classes. In this way those prototype applications which I released a decade ago will still run in the latest version of the framework and will automatically include any enhancements (except where new features require new code).
It is important to note that this framework cannot be used to build public-facing web sites, it is only for business-facing web applications. If you do not understand the difference then I suggest you read Web Site vs Web Application.
As well as creating a framework for building applications I have actually eaten my own dogfood and used it to create a large enterprise application as a software package. I started with nothing more than the database designs I found in Len Silverston's Data Model Resource Book. Each of these database designs covers a particular area in a comprehensive yet flexible manner, and as soon as I came across them I could see the benefit of using them as a starting point for my own application. This to me was a match made in heaven - I had created a framework for building entire applications starting with nothing more than the database schema, and here was a book of schemas just crying out to be turned into an application. All I had to do was import the schemas into my Data Dictionary, generate the basic class files and user transactions, then add in the custom code to deal with the complex business rules. I started work in January 2007 and within six months I had created working examples of the following databases:
If you can count you should realise that that averages out at one database/subsystem per calendar month. I honestly do not believe that I could have achieved that level of productivity if I had used a "proper" design methodology.
This application, with the name TRANSIX, went live with its first customer in 2008 after I had modified their existing front-end website to use the new database instead of their old one, and to add in new functionality. Since then I have also added the following subsystems:
One important aspect of selling a software package which can be used by multiple organisations is that each of those organisations will be bound to have their own specialised requirements in certain areas which means that the standard code will not be sufficient. In order to cater for this common requirement I have designed a mechanism whereby any customisations required by individual customers can be maintained as separate plug-in modules. These plug-ins are held in separate directories from the standard code, with separate subdirectories for each customer. At runtime the framework will look for plug-ins for the current customer, and if any are found they will be processed automatically.
This software currently deals with 300+ database tables, 500+ relationships and 2,500+ user transactions, so it cannot be described as a "trivial" application by any stretch of the imagination. It is suitable for world-wide consumption as it is multi-lingual, multi-currency, multi-timezone and multi-calendar.
In 2014 I met the chairman and president of Geoprise Technologies Corporation who build and market software in America, Asia and the Pacific Rim. His company had already used my framework to build their own applications, so I showed him my TRANSIX software and asked if it had any value to him. He was impressed enough to offer me a Joint Venture Partnership and make me Director, Research and Development. Shortly after that we won a contract to supply software to a major aerospace company in Singapore. None of this would have been possible if my software was as bad as my critics would have you believe.
In his book Visualising Software Architecture the author Simon Brown makes the following complaint:
Ask somebody in the building industry to visually communicate the architecture of a building and you'll likely be presented with site plans, floor plans, elevation views, cross-section views and detail drawings. In contrast, ask a software developer to communicate the software architecture of a software system using diagrams and you'll likely get a confused mess of boxes and lines.
I've asked thousands of software developers to do just this over the past decade and continue to do so today. The results still surprise me, with the thousands of photos taken during these software architecture sketching workshops suggesting that effective visual communication of software architecture is a skill that's sorely lacking in the software development industry.
Now take a look at the diagram I have produced in Figure 17 to show the structure of my development framework:
Figure 17 - detailed structure diagram
")
Note that in the above diagram each of the numbered components is a clickable link.
If you cannot produce such a simple yet comprehensive diagram of your application architecture then perhaps it just proves that your architecture is a total mess to begin with. Or perhaps it points to the fact that I have artistic abilities (some people refer to me as a Piss Artist) which, coupled with my logical mind, makes me a better designer/builder than most of my contemporaries. If not actually better then less incompetent.
By following the KISS Principle I write simple code to do complex things, not complex code to do simple things. Each time a new feature is added to the language I do not jump on the bandwagon and look for ways to squeeze it into my code. If I have already got code that works then I don't change it to incorporate a new feature unless that new feature provides measurable benefits, such as being able to replace a large block of code with something significantly smaller.
I originally wrote my code for PHP 4, and after PHP 5 was released it had a very slow take-up, so I had to find a way to support both versions in my open source codebase and not, as some other frameworks did, create separate versions of my code for each version of the language. My only problem was the fact my code used the XML and XSLT extensions, and these were changed between PHP 4 and PHP 5. To solve this I used a technique similar to what I had used over a decade earlier when the HP3000 moved from the classic chip architecture to PA-RISC. Where there were differences in the code I put this code into wrapper functions which I maintained in a library. I had two versions of this library, one classic and another RISC, and two versions of the batch job which created the executables using the right version of the compiler with the corresponding version of the library. Only one version of the application source code was maintained by the developers, and it was possible to produce two versions of the application, one classic and another RISC, simply by running the relevant batch job. With PHP it was much simpler as all the XML and XSL code was in the same class, so I could create one version of this class for PHP 4 and another for PHP 5. At runtime I could load the relevant class with this simple code:
if (version_compare(phpversion(), '5.0.0', '<')) { require_once 'include.xml.php4.inc'; } else { require_once 'include.xml.php5.inc'; } // if
Although lots of new features have been added to PHP 5, the only one I have actually found a use for is the DateTime functionality. In order to incorporate this into my codebase I did the following when I needed to manipulate a date:
if (version_compare(phpversion(), '5.2.0', '>=')) { ... do it the new way } else { ... do it the old way } // if
The end result of not using any fancy new features, or not using them in a fancy way, was that whenever a new version of PHP was released I could simply install it and my code would run. I did not have to waste time looking for BC breaks or where a recently added feature had changed, and none of my users had to download a separate version of my framework which was compatible with a particular version of the language. That is why my framework is still capable of being run on any version of PHP, including version 4. I do not plan to officially drop support for PHP 4 until I start supporting PHP 7 as the differences cannot be contained in a single place.
Anyone who thinks that OOP is not suitable for database applications is just plain wrong. It is not OOP per se, it is probably because that person's definition of OOP, and their subsequent dodgy implementation of that dodgy definition which is wrong. When I researched the meaning of OOP in 2002 I found this description:
Object Oriented Programming is programming which is oriented around objects, thus taking advantage of Encapsulation, Polymorphism, and Inheritance to increase code reuse and decrease code maintenance.
When I started to redevelop my framework using PHP I did not follow these things called "best practices" and "approved programming principles" simply because I did not know that they existed. There was no mention of them in the PHP manual, so I simply wrote my code using the facilities which the PHP language made available, namely encapsulation, inheritance and polymorphism. I was able to build a much larger collection of reusable code than I had done previously using COBOL and UNIFACE, which meant that I could create new components at a much faster rate, so I judged my efforts to be a success. Upon being informed that my work was totally wrong simply because I was not following the same rules as everyone else, I took a look at these rules but I decided that by trying to follow them I would be destroying what I had already achieved. It became obvious to me that the people who wrote these rules had little or no experience of developing web-based database applications, so their rules could only be applied in the domain for which they were written and were irrelevant for the domain in which I worked.
The fact that OOD/OOP enables you to model the real world is irrelevant unless you are writing software which interacts directly with objects or entities in the real world. If you are writing software which interacts with tables in a database then you should tailor your solution to deal ONLY with the properties and methods which apply to tables in a database. This is why every one of my Model classes in the Business layer is built around a single database table. Yet as soon as I wrote an article explaining this simple concept I was told most emphatically that Having a separate class for each database table is not good OO.
The person who made the following statement is also wrong:
If you have one class per database table you are relegating each class to being no more than a simple transport mechanism for moving data between the database and the user interface. It is supposed to be more complicated than that.
What this person has failed to understand, probably due to a lack of experience, is that when writing a database application you are writing software which interacts with objects in a database, not objects in the "real world", and those objects are called "tables". The only operations which can be performed on a database table are Create, Read, Update and Delete (CRUD). Different combinations of these operations are performed on different combinations of tables by performing a collection of user transactions. The basic functionality of every user transaction always follows the same basic pattern - it performs one or more CRUD operations on one or more tables. It starts out as being nothing more than a "simple transport mechanism" as it entails the moving of data between the user interface, through the Business layer, to a Database layer and back again. It is the Business layer which is the heart of the application as this is where all the business rules are processed. In the RADICORE framework all standard functionality, up to and including all primary validation, is provided by components which are built into the framework. Any complex business rules can be added in later by the developer by inserting the relevant code into any of the numerous "hook" methods within any table subclass. In other words the framework provides all the simple processing while it is the developer's responsibility to add in any complexities.
Some developers still employ a technique which involves starting with the business rules and then plugging in the boilerplate code. My technique is the reverse - the framework provides the boilerplate code in an abstract table class after which the developer plugs in the business rules in the relevant "hook" methods within each concrete table class. Additional boilerplate code for each task (user transaction) is provided by the framework in the form of reusable page controllers.
I have been building database applications for several decades in several different languages, and in that time I have built thousands of programs. Every one of these, regardless of which business domain they are in, follows the same pattern in that they perform one or more CRUD operations on one or more database tables aided by a screen (which nowadays is HTML) on the client device. This part of the program's functionality, the moving of data between the client device and the database, is so similar that it can be provided using boilerplate code which can, in turn, be provided by the framework. Every complicated program starts off by being a simple program which can be expanded by adding business rules which cannot be covered by the framework. The standard code is provided by a series of Template Methods which are defined within an abstract table class. This then allows any business rules to be included in any table subclass simply by adding the necessary code into any of the predefined hook methods. The standard, basic functionality is provided by the framework while the complicated business rules are added by the programmer.
Another problem I have with today's OO theory is that it is being taught as the only way to implement OO "properly". I have never seen any articles saying "it could be done either this way or that way", just "it should be done this way". Anyone who deviates from the official view is immediately branded as a heretic or a dunce - just take a look at What is/is not considered to be good OO programming and Your code is crap! if you don't believe me.
The new generation of programmers is not being taught to think for themselves, they are taught merely to obey! As far as I am concerned there is no such thing as "only one way" to do anything. In my COBOL days there were many different attempts by different authors to define a "better" design methodology or "better" development standards, and while some developers chose to pick one of these methodologies (or had the choice imposed upon them by management) and adopt it 100% to the exclusion of all others, I and my colleagues decided on the pick'n'mix approach were we took the bits that we liked from a number of different methodologies and combined them with bits of our own invention in order to come up with something that we liked and which worked for us. It may have resulted in a patchwork quilt of ideas, but it worked for us, and that is the only fact worth considering.
Another thing I have noticed many times in my long career is while it is possible to use any technique or methodology, it is also possible to over-use it, mis-use it or even ab-use it. There is no such thing as a "one size fits all" solution, there are numerous alternatives which can be used in different circumstances or where appropriate. The trouble is that too many of today's developers do not have the mental capacity to determine if something is appropriate or not, so they go ahead and use it everywhere. This is why in my 2004 article entitled Technical Keys - Their Uses and Abuses I wrote the following:
There are two ways of using technical primary keys - intelligently and indiscriminately.
The same thing can be said for any of today's OO techniques. Just swap the words "technical primary keys" for any aspect of OOD or OOP and you will come across a large number of people who fall into the "indiscriminate" camp and who therefore show a lack of intelligence.
By insisting that there is only "one true way" the teachers of the next generation are doing that generation a great disservice. By adopting a closed mind attitude which is akin to religious dogma they are preventing the next generation from exploring all the available options and perhaps coming up with new and better options. They should be teaching their students how to think, not what to think. Progress, after all, can only be achieved by doing something which is different. If you are forced to be the same as everyone just to conform or to be consistent, then you will always be a drone and not an individual. You will always be a sheep and not a shepherd. You will always be a code monkey and not an organ grinder.
I am not a dogmatic programmer who is rules-oriented, I am a pragmatic programmer who is results-oriented. I don't follow the herd, I am a maverick. I do not follow the orthodox view without question, I am a heretic. I do not engage in Buzzword Driven Development or Cargo Cult Programming. Rather than being one to Jump on the Bandwagon I prefer to Dump on the Bandwagon. I don't write code to please other programmers, I write code to please my paying customers, and all the while I have customers knocking on my door I shall continue doing what I do and laugh all the way to bank while you are finding more and more complex and ridiculous ways to do such simple things.
Here endeth the lesson. Don't applaud, just throw money.
The following articles describe aspects of my framework:
The following articles express my heretical views on the topic of OOP:
These are reasons why I consider some ideas on how to do OOP "properly" to be complete rubbish:
Here are my views on changes to the PHP language and Backwards Compatibility:
The following are responses to criticisms of my methods:
Here are some miscellaneous articles:
| 04 Feb 2023 | Refined contents of Databases do not have Associations
Refined contents of Databases do not have Compositions Refined contents of Databases do not have Aggregations |